From 4899d56d9a1ff9360ae87c650fc4c6bf0fef63b4 Mon Sep 17 00:00:00 2001
From: BorderArea01 <3109362852@qq.com>
Date: Fri, 24 Apr 2026 19:34:41 +0800
Subject: [PATCH] first commit
---
LICENSE | 201 ++
MANIFEST.in | 13 +
README.md | 1361 ++++++++++
assets/Qwen3_TTS.pdf | Bin 0 -> 8044886 bytes
examples/test_model_12hz_base.py | 192 ++
examples/test_model_12hz_custom_voice.py | 77 +
examples/test_model_12hz_voice_design.py | 80 +
examples/test_tokenizer_12hz.py | 65 +
finetuning/README.md | 121 +
finetuning/dataset.py | 218 ++
finetuning/prepare_data.py | 71 +
finetuning/sft_12hz.py | 161 ++
pyproject.toml | 46 +
qwen_tts/__init__.py | 24 +
qwen_tts/__main__.py | 24 +
qwen_tts/cli/demo.py | 634 +++++
qwen_tts/core/__init__.py | 19 +
qwen_tts/core/models/__init__.py | 18 +
.../core/models/configuration_qwen3_tts.py | 502 ++++
qwen_tts/core/models/modeling_qwen3_tts.py | 2299 +++++++++++++++++
qwen_tts/core/models/processing_qwen3_tts.py | 106 +
.../configuration_qwen3_tts_tokenizer_v2.py | 172 ++
.../modeling_qwen3_tts_tokenizer_v2.py | 1027 ++++++++
.../configuration_qwen3_tts_tokenizer_v1.py | 332 +++
.../modeling_qwen3_tts_tokenizer_v1.py | 1529 +++++++++++
.../tokenizer_25hz/vq/assets/mel_filters.npz | Bin 0 -> 4271 bytes
qwen_tts/core/tokenizer_25hz/vq/core_vq.py | 523 ++++
qwen_tts/core/tokenizer_25hz/vq/speech_vq.py | 357 +++
.../core/tokenizer_25hz/vq/whisper_encoder.py | 406 +++
qwen_tts/inference/qwen3_tts_model.py | 877 +++++++
qwen_tts/inference/qwen3_tts_tokenizer.py | 411 +++
31 files changed, 11866 insertions(+)
create mode 100644 LICENSE
create mode 100644 MANIFEST.in
create mode 100644 README.md
create mode 100644 assets/Qwen3_TTS.pdf
create mode 100644 examples/test_model_12hz_base.py
create mode 100644 examples/test_model_12hz_custom_voice.py
create mode 100644 examples/test_model_12hz_voice_design.py
create mode 100644 examples/test_tokenizer_12hz.py
create mode 100644 finetuning/README.md
create mode 100644 finetuning/dataset.py
create mode 100644 finetuning/prepare_data.py
create mode 100644 finetuning/sft_12hz.py
create mode 100644 pyproject.toml
create mode 100644 qwen_tts/__init__.py
create mode 100644 qwen_tts/__main__.py
create mode 100644 qwen_tts/cli/demo.py
create mode 100644 qwen_tts/core/__init__.py
create mode 100644 qwen_tts/core/models/__init__.py
create mode 100644 qwen_tts/core/models/configuration_qwen3_tts.py
create mode 100644 qwen_tts/core/models/modeling_qwen3_tts.py
create mode 100644 qwen_tts/core/models/processing_qwen3_tts.py
create mode 100644 qwen_tts/core/tokenizer_12hz/configuration_qwen3_tts_tokenizer_v2.py
create mode 100644 qwen_tts/core/tokenizer_12hz/modeling_qwen3_tts_tokenizer_v2.py
create mode 100644 qwen_tts/core/tokenizer_25hz/configuration_qwen3_tts_tokenizer_v1.py
create mode 100644 qwen_tts/core/tokenizer_25hz/modeling_qwen3_tts_tokenizer_v1.py
create mode 100644 qwen_tts/core/tokenizer_25hz/vq/assets/mel_filters.npz
create mode 100644 qwen_tts/core/tokenizer_25hz/vq/core_vq.py
create mode 100644 qwen_tts/core/tokenizer_25hz/vq/speech_vq.py
create mode 100644 qwen_tts/core/tokenizer_25hz/vq/whisper_encoder.py
create mode 100644 qwen_tts/inference/qwen3_tts_model.py
create mode 100644 qwen_tts/inference/qwen3_tts_tokenizer.py
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 0000000..c347eb5
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright 2026 Alibaba Cloud
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/MANIFEST.in b/MANIFEST.in
new file mode 100644
index 0000000..aa79178
--- /dev/null
+++ b/MANIFEST.in
@@ -0,0 +1,13 @@
+global-exclude *
+
+recursive-include qwen_tts *.py *.pyi py.typed
+recursive-include qwen_tts *.npz
+
+include LICENSE
+include MANIFEST.in
+include pyproject.toml
+
+prune assets
+prune examples
+prune finetuning
+prune qwen_tts.egg-info
\ No newline at end of file
diff --git a/README.md b/README.md
new file mode 100644
index 0000000..8287bac
--- /dev/null
+++ b/README.md
@@ -0,0 +1,1361 @@
+# Qwen3-TTS
+
+
+
+
+  +
+
+
+
+ 🤗 Hugging Face | 🤖 ModelScope | 📑 Blog | 📑 Paper
+
+🖥️ Hugging Face Demo | 🖥️ ModelScope Demo | 💬 WeChat (微信) | 🫨 Discord | 📑 API
+
+
+
+We release **Qwen3-TTS**, a series of powerful speech generation capabilities developed by Qwen, offering comprehensive support for voice clone, voice design, ultra-high-quality human-like speech generation, and natural language-based voice control. It provides developers and users with the most extensive set of speech generation features available.
+
+
+## News
+* 2026.1.22: 🎉🎉🎉 We have released [Qwen3-TTS](https://huggingface.co/collections/Qwen/qwen3-tts) series (0.6B/1.7B) based on Qwen3-TTS-Tokenizer-12Hz. Please check our [blog](https://qwen.ai/blog?id=qwen3tts-0115)!
+
+## Contents
+
+- [Overview](#overview)
+ - [Introduction](#introduction)
+ - [Model Architecture](#model-architecture)
+ - [Released Models Description and Download](#released-models-description-and-download)
+- [Quickstart](#quickstart)
+ - [Environment Setup](#environment-setup)
+ - [Python Package Usage](#python-package-usage)
+ - [Custom Voice Generation](#custom-voice-generate)
+ - [Voice Design](#voice-design)
+ - [Voice Clone](#voice-clone)
+ - [Voice Design then Clone](#voice-design-then-clone)
+ - [Tokenizer Encode and Decode](#tokenizer-encode-and-decode)
+ - [Launch Local Web UI Demo](#launch-local-web-ui-demo)
+ - [DashScope API Usage](#dashscope-api-usage)
+- [vLLM Usage](#vllm-usage)
+- [Fine Tuning](#fine-tuning)
+- [Evaluation](#evaluation)
+- [Citation](#citation)
+
+## Overview
+### Introduction
+
+
+  +
+
+
+Qwen3-TTS covers 10 major languages (Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, and Italian) as well as multiple dialectal voice profiles to meet global application needs. In addition, the models feature strong contextual understanding, enabling adaptive control of tone, speaking rate, and emotional expression based on instructions and text semantics, and they show markedly improved robustness to noisy input text. Key features:
+
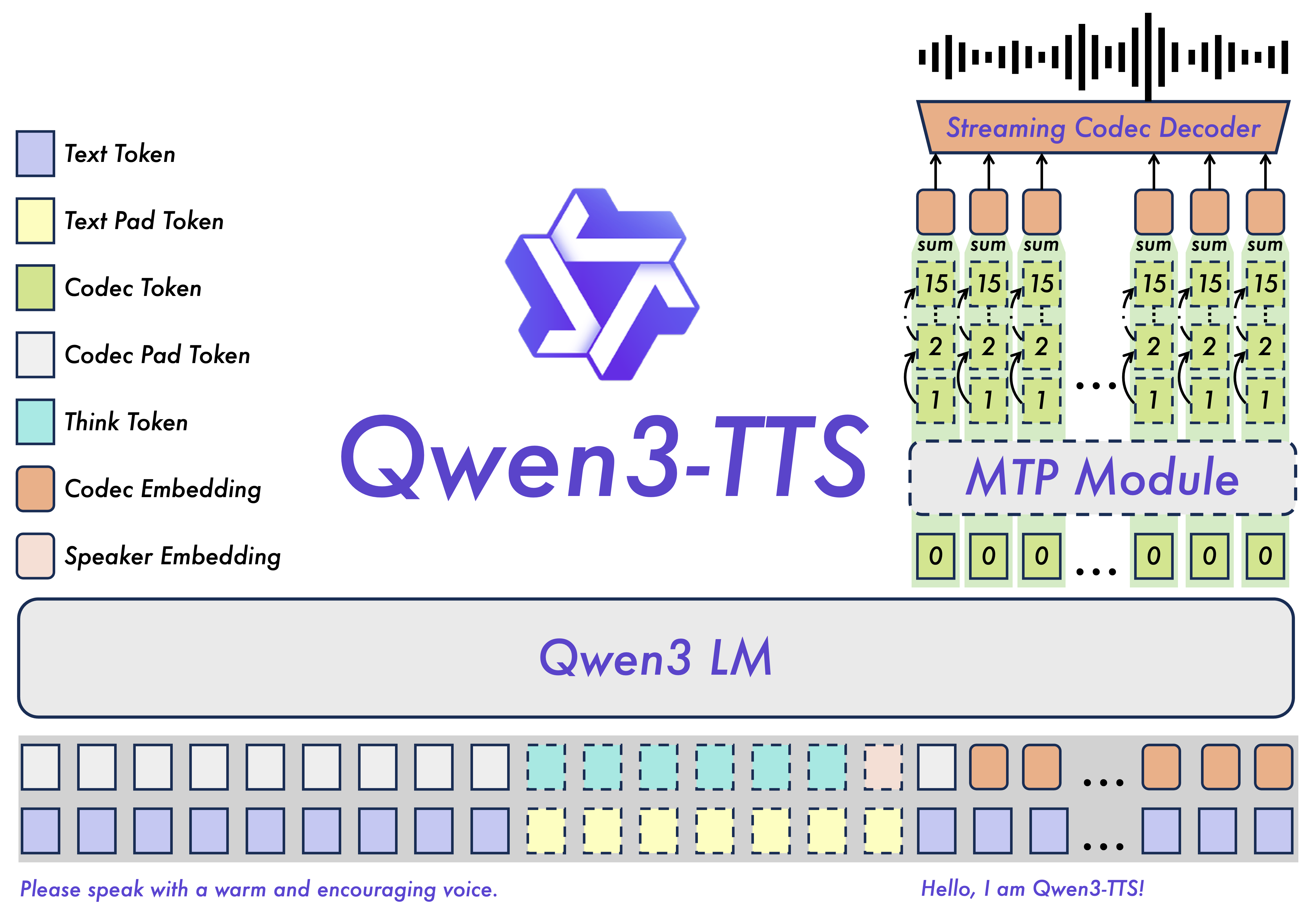
+* **Powerful Speech Representation**: Powered by the self-developed Qwen3-TTS-Tokenizer-12Hz, it achieves efficient acoustic compression and high-dimensional semantic modeling of speech signals. It fully preserves paralinguistic information and acoustic environmental features, enabling high-speed, high-fidelity speech reconstruction through a lightweight non-DiT architecture.
+* **Universal End-to-End Architecture**: Utilizing a discrete multi-codebook LM architecture, it realizes full-information end-to-end speech modeling. This completely bypasses the information bottlenecks and cascading errors inherent in traditional LM+DiT schemes, significantly enhancing the model’s versatility, generation efficiency, and performance ceiling.
+* **Extreme Low-Latency Streaming Generation**: Based on the innovative Dual-Track hybrid streaming generation architecture, a single model supports both streaming and non-streaming generation. It can output the first audio packet immediately after a single character is input, with end-to-end synthesis latency as low as 97ms, meeting the rigorous demands of real-time interactive scenarios.
+* **Intelligent Text Understanding and Voice Control**: Supports speech generation driven by natural language instructions, allowing for flexible control over multi-dimensional acoustic attributes such as timbre, emotion, and prosody. By deeply integrating text semantic understanding, the model adaptively adjusts tone, rhythm, and emotional expression, achieving lifelike “what you imagine is what you hear” output.
+
+
+### Model Architecture
+
+
+  +
+
+
+### Released Models Description and Download
+
+Below is an introduction and download information for the Qwen3-TTS models that have already been released. Other models mentioned in the technical report will be released in the near future. Please select and download the model that fits your needs.
+
+| Tokenizer Name | Description |
+|---------------------------------|-------------|
+| Qwen3-TTS-Tokenizer-12Hz | The Qwen3-TTS-Tokenizer-12Hz model which can encode the input speech into codes and decode them back into speech. |
+
+
+| Model | Features | Language Support | Streaming | Instruction Control |
+|---|---|---|---|---|
+| Qwen3-TTS-12Hz-1.7B-VoiceDesign | Performs voice design based on user-provided descriptions. | Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian | ✅ | ✅ |
+| Qwen3-TTS-12Hz-1.7B-CustomVoice | Provides style control over target timbres via user instructions; supports 9 premium timbres covering various combinations of gender, age, language, and dialect. | Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian | ✅ | ✅ |
+| Qwen3-TTS-12Hz-1.7B-Base | Base model capable of 3-second rapid voice clone from user audio input; can be used for fine-tuning (FT) other models. | Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian | ✅ | |
+| Qwen3-TTS-12Hz-0.6B-CustomVoice | Supports 9 premium timbres covering various combinations of gender, age, language, and dialect. | Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian | ✅ | |
+| Qwen3-TTS-12Hz-0.6B-Base | Base model capable of 3-second rapid voice clone from user audio input; can be used for fine-tuning (FT) other models. | Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian | ✅ | |
+
+During model loading in the qwen-tts package or vLLM, model weights will be automatically downloaded based on the model name. However, if your runtime environment is not conducive to downloading weights during execution, you can refer to the following commands to manually download the model weights to a local directory:
+
+```bash
+# Download through ModelScope (recommended for users in Mainland China)
+pip install -U modelscope
+modelscope download --model Qwen/Qwen3-TTS-Tokenizer-12Hz --local_dir ./Qwen3-TTS-Tokenizer-12Hz
+modelscope download --model Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice --local_dir ./Qwen3-TTS-12Hz-1.7B-CustomVoice
+modelscope download --model Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign --local_dir ./Qwen3-TTS-12Hz-1.7B-VoiceDesign
+modelscope download --model Qwen/Qwen3-TTS-12Hz-1.7B-Base --local_dir ./Qwen3-TTS-12Hz-1.7B-Base
+modelscope download --model Qwen/Qwen3-TTS-12Hz-0.6B-CustomVoice --local_dir ./Qwen3-TTS-12Hz-0.6B-CustomVoice
+modelscope download --model Qwen/Qwen3-TTS-12Hz-0.6B-Base --local_dir ./Qwen3-TTS-12Hz-0.6B-Base
+
+# Download through Hugging Face
+pip install -U "huggingface_hub[cli]"
+huggingface-cli download Qwen/Qwen3-TTS-Tokenizer-12Hz --local-dir ./Qwen3-TTS-Tokenizer-12Hz
+huggingface-cli download Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice --local-dir ./Qwen3-TTS-12Hz-1.7B-CustomVoice
+huggingface-cli download Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign --local-dir ./Qwen3-TTS-12Hz-1.7B-VoiceDesign
+huggingface-cli download Qwen/Qwen3-TTS-12Hz-1.7B-Base --local-dir ./Qwen3-TTS-12Hz-1.7B-Base
+huggingface-cli download Qwen/Qwen3-TTS-12Hz-0.6B-CustomVoice --local-dir ./Qwen3-TTS-12Hz-0.6B-CustomVoice
+huggingface-cli download Qwen/Qwen3-TTS-12Hz-0.6B-Base --local-dir ./Qwen3-TTS-12Hz-0.6B-Base
+```
+
+
+## Quickstart
+
+### Environment Setup
+
+The easiest way to quickly use Qwen3-TTS is to install the `qwen-tts` Python package from PyPI. This will pull in the required runtime dependencies and allow you to load any released Qwen3-TTS model. We recommend using a **fresh, isolated environment** to avoid dependency conflicts with existing packages. You can create a clean Python 3.12 environment like this:
+
+```bash
+conda create -n qwen3-tts python=3.12 -y
+conda activate qwen3-tts
+```
+
+then run:
+
+```bash
+pip install -U qwen-tts
+```
+
+If you want to develop or modify the code locally, install from source in editable mode.
+
+```bash
+git clone https://github.com/QwenLM/Qwen3-TTS.git
+cd Qwen3-TTS
+pip install -e .
+```
+
+Additionally, we recommend using FlashAttention 2 to reduce GPU memory usage.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+If your machine has less than 96GB of RAM and lots of CPU cores, run:
+
+```bash
+MAX_JOBS=4 pip install -U flash-attn --no-build-isolation
+```
+
+Also, you should have hardware that is compatible with FlashAttention 2. Read more about it in the official documentation of the [FlashAttention repository](https://github.com/Dao-AILab/flash-attention). FlashAttention 2 can only be used when a model is loaded in `torch.float16` or `torch.bfloat16`.
+
+
+### Python Package Usage
+
+After installation, you can import `Qwen3TTSModel` to run custom voice TTS, voice design, and voice clone. The model weights can be specified either as a Hugging Face model id (recommended) or as a local directory path you downloaded. For all the `generate_*` functions below, besides the parameters shown and explicitly documented, you can also pass generation kwargs supported by Hugging Face Transformers `model.generate`, e.g., `max_new_tokens`, `top_p`, etc.
+
+#### Custom Voice Generate
+
+For custom voice models (`Qwen3-TTS-12Hz-1.7B/0.6B-CustomVoice`), you just need to call `generate_custom_voice`, passing a single string or a batch list, along with `language`, `speaker`, and optional `instruct`. You can also call `model.get_supported_speakers()` and `model.get_supported_languages()` to see which speakers and languages the current model supports.
+
+```python
+import torch
+import soundfile as sf
+from qwen_tts import Qwen3TTSModel
+
+model = Qwen3TTSModel.from_pretrained(
+ "Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice",
+ device_map="cuda:0",
+ dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+)
+
+# single inference
+wavs, sr = model.generate_custom_voice(
+ text="其实我真的有发现,我是一个特别善于观察别人情绪的人。",
+ language="Chinese", # Pass `Auto` (or omit) for auto language adaptive; if the target language is known, set it explicitly.
+ speaker="Vivian",
+ instruct="用特别愤怒的语气说", # Omit if not needed.
+)
+sf.write("output_custom_voice.wav", wavs[0], sr)
+
+# batch inference
+wavs, sr = model.generate_custom_voice(
+ text=[
+ "其实我真的有发现,我是一个特别善于观察别人情绪的人。",
+ "She said she would be here by noon."
+ ],
+ language=["Chinese", "English"],
+ speaker=["Vivian", "Ryan"],
+ instruct=["", "Very happy."]
+)
+sf.write("output_custom_voice_1.wav", wavs[0], sr)
+sf.write("output_custom_voice_2.wav", wavs[1], sr)
+```
+
+For `Qwen3-TTS-12Hz-1.7B/0.6B-CustomVoice` models, the supported speaker list and speaker descriptions are provided below. We recommend using each speaker’s native language for the best quality. Of course, each speaker can speak any language supported by the model.
+
+| Speaker | Voice Description | Native language |
+| --- | --- | --- |
+| Vivian | Bright, slightly edgy young female voice. | Chinese |
+| Serena | Warm, gentle young female voice. | Chinese |
+| Uncle_Fu | Seasoned male voice with a low, mellow timbre. | Chinese |
+| Dylan | Youthful Beijing male voice with a clear, natural timbre. | Chinese (Beijing Dialect) |
+| Eric | Lively Chengdu male voice with a slightly husky brightness. | Chinese (Sichuan Dialect) |
+| Ryan | Dynamic male voice with strong rhythmic drive. | English |
+| Aiden | Sunny American male voice with a clear midrange. | English |
+| Ono_Anna | Playful Japanese female voice with a light, nimble timbre. | Japanese |
+| Sohee | Warm Korean female voice with rich emotion. | Korean |
+
+#### Voice Design
+
+For the voice design model (`Qwen3-TTS-12Hz-1.7B-VoiceDesign`), you can use `generate_voice_design` to provide the target text and a natural-language `instruct` description.
+
+```python
+import torch
+import soundfile as sf
+from qwen_tts import Qwen3TTSModel
+
+model = Qwen3TTSModel.from_pretrained(
+ "Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign",
+ device_map="cuda:0",
+ dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+)
+
+# single inference
+wavs, sr = model.generate_voice_design(
+ text="哥哥,你回来啦,人家等了你好久好久了,要抱抱!",
+ language="Chinese",
+ instruct="体现撒娇稚嫩的萝莉女声,音调偏高且起伏明显,营造出黏人、做作又刻意卖萌的听觉效果。",
+)
+sf.write("output_voice_design.wav", wavs[0], sr)
+
+# batch inference
+wavs, sr = model.generate_voice_design(
+ text=[
+ "哥哥,你回来啦,人家等了你好久好久了,要抱抱!",
+ "It's in the top drawer... wait, it's empty? No way, that's impossible! I'm sure I put it there!"
+ ],
+ language=["Chinese", "English"],
+ instruct=[
+ "体现撒娇稚嫩的萝莉女声,音调偏高且起伏明显,营造出黏人、做作又刻意卖萌的听觉效果。",
+ "Speak in an incredulous tone, but with a hint of panic beginning to creep into your voice."
+ ]
+)
+sf.write("output_voice_design_1.wav", wavs[0], sr)
+sf.write("output_voice_design_2.wav", wavs[1], sr)
+```
+
+#### Voice Clone
+
+For the voice clone model (`Qwen3-TTS-12Hz-1.7B/0.6B-Base`), to clone a voice and synthesize new content, you just need to provide a reference audio clip (`ref_audio`) along with its transcript (`ref_text`). `ref_audio` can be a local file path, a URL, a base64 string, or a `(numpy_array, sample_rate)` tuple. If you set `x_vector_only_mode=True`, only the speaker embedding is used so `ref_text` is not required, but cloning quality may be reduced.
+
+```python
+import torch
+import soundfile as sf
+from qwen_tts import Qwen3TTSModel
+
+model = Qwen3TTSModel.from_pretrained(
+ "Qwen/Qwen3-TTS-12Hz-1.7B-Base",
+ device_map="cuda:0",
+ dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+)
+
+ref_audio = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-TTS-Repo/clone.wav"
+ref_text = "Okay. Yeah. I resent you. I love you. I respect you. But you know what? You blew it! And thanks to you."
+
+wavs, sr = model.generate_voice_clone(
+ text="I am solving the equation: x = [-b ± √(b²-4ac)] / 2a? Nobody can — it's a disaster (◍•͈⌔•͈◍), very sad!",
+ language="English",
+ ref_audio=ref_audio,
+ ref_text=ref_text,
+)
+sf.write("output_voice_clone.wav", wavs[0], sr)
+```
+
+If you need to reuse the same reference prompt across multiple generations (to avoid recomputing prompt features), build it once with `create_voice_clone_prompt` and pass it via `voice_clone_prompt`.
+
+```python
+prompt_items = model.create_voice_clone_prompt(
+ ref_audio=ref_audio,
+ ref_text=ref_text,
+ x_vector_only_mode=False,
+)
+wavs, sr = model.generate_voice_clone(
+ text=["Sentence A.", "Sentence B."],
+ language=["English", "English"],
+ voice_clone_prompt=prompt_items,
+)
+sf.write("output_voice_clone_1.wav", wavs[0], sr)
+sf.write("output_voice_clone_2.wav", wavs[1], sr)
+```
+
+For more examples of reusable voice clone prompts, batch cloning, and batch inference, please refer to the [example codes](https://github.com/QwenLM/Qwen3-TTS/blob/main/examples/test_model_12hz_base.py). With those examples and the `generate_voice_clone` function description, you can explore more advanced usage patterns.
+
+#### Voice Design then Clone
+
+If you want a designed voice that you can reuse like a cloned speaker, a practical workflow is: (1) use the **VoiceDesign** model to synthesize a short reference clip that matches your target persona, (2) feed that clip into `create_voice_clone_prompt` to build a reusable prompt, and then (3) call `generate_voice_clone` with `voice_clone_prompt` to generate new content without re-extracting features every time. This is especially useful when you want a consistent character voice across many lines.
+
+```python
+import torch
+import soundfile as sf
+from qwen_tts import Qwen3TTSModel
+
+# create a reference audio in the target style using the VoiceDesign model
+design_model = Qwen3TTSModel.from_pretrained(
+ "Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign",
+ device_map="cuda:0",
+ dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+)
+
+ref_text = "H-hey! You dropped your... uh... calculus notebook? I mean, I think it's yours? Maybe?"
+ref_instruct = "Male, 17 years old, tenor range, gaining confidence - deeper breath support now, though vowels still tighten when nervous"
+ref_wavs, sr = design_model.generate_voice_design(
+ text=ref_text,
+ language="English",
+ instruct=ref_instruct
+)
+sf.write("voice_design_reference.wav", ref_wavs[0], sr)
+
+# build a reusable clone prompt from the voice design reference
+clone_model = Qwen3TTSModel.from_pretrained(
+ "Qwen/Qwen3-TTS-12Hz-1.7B-Base",
+ device_map="cuda:0",
+ dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+)
+
+voice_clone_prompt = clone_model.create_voice_clone_prompt(
+ ref_audio=(ref_wavs[0], sr), # or "voice_design_reference.wav"
+ ref_text=ref_text,
+)
+
+sentences = [
+ "No problem! I actually... kinda finished those already? If you want to compare answers or something...",
+ "What? No! I mean yes but not like... I just think you're... your titration technique is really precise!",
+]
+
+# reuse it for multiple single calls
+wavs, sr = clone_model.generate_voice_clone(
+ text=sentences[0],
+ language="English",
+ voice_clone_prompt=voice_clone_prompt,
+)
+sf.write("clone_single_1.wav", wavs[0], sr)
+
+wavs, sr = clone_model.generate_voice_clone(
+ text=sentences[1],
+ language="English",
+ voice_clone_prompt=voice_clone_prompt,
+)
+sf.write("clone_single_2.wav", wavs[0], sr)
+
+# or batch generate in one call
+wavs, sr = clone_model.generate_voice_clone(
+ text=sentences,
+ language=["English", "English"],
+ voice_clone_prompt=voice_clone_prompt,
+)
+for i, w in enumerate(wavs):
+ sf.write(f"clone_batch_{i}.wav", w, sr)
+```
+
+#### Tokenizer Encode and Decode
+
+If you only want to encode and decode audio for transport or training and so on, `Qwen3TTSTokenizer` supports encode/decode with paths, URLs, numpy waveforms, and dict/list payloads, for example:
+
+```python
+import soundfile as sf
+from qwen_tts import Qwen3TTSTokenizer
+
+tokenizer = Qwen3TTSTokenizer.from_pretrained(
+ "Qwen/Qwen3-TTS-Tokenizer-12Hz",
+ device_map="cuda:0",
+)
+
+enc = tokenizer.encode("https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-TTS-Repo/tokenizer_demo_1.wav")
+wavs, sr = tokenizer.decode(enc)
+sf.write("decode_output.wav", wavs[0], sr)
+```
+
+For more tokenizer examples (including different input formats and batch usage), please refer to the [example codes](https://github.com/QwenLM/Qwen3-TTS/blob/main/examples/test_tokenizer_12hz.py). With those examples and the description for `Qwen3TTSTokenizer`, you can explore more advanced usage patterns.
+
+### Launch Local Web UI Demo
+
+To launch the Qwen3-TTS web ui demo, simply install the `qwen-tts` package and run `qwen-tts-demo`. Use the command below for help:
+
+```bash
+qwen-tts-demo --help
+```
+
+To launch the demo, you can use the following commands:
+
+```bash
+# CustomVoice model
+qwen-tts-demo Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice --ip 0.0.0.0 --port 8000
+# VoiceDesign model
+qwen-tts-demo Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign --ip 0.0.0.0 --port 8000
+# Base model
+qwen-tts-demo Qwen/Qwen3-TTS-12Hz-1.7B-Base --ip 0.0.0.0 --port 8000
+```
+
+And then open `http://:8000`, or access it via port forwarding in tools like VS Code.
+
+#### Base Model HTTPS Notes
+
+To avoid browser microphone permission issues after deploying the server, for Base model deployments, it is recommended/required to run the gradio service over **HTTPS** (especially when accessed remotely or behind modern browsers/gateways). Use `--ssl-certfile` and `--ssl-keyfile` to enable HTTPS. First we need to generate a private key and a self-signed cert (valid for 365 days):
+
+```bash
+openssl req -x509 -newkey rsa:2048 \
+ -keyout key.pem -out cert.pem \
+ -days 365 -nodes \
+ -subj "/CN=localhost"
+```
+
+Then run the demo with HTTPS:
+
+```bash
+qwen-tts-demo Qwen/Qwen3-TTS-12Hz-1.7B-Base \
+ --ip 0.0.0.0 --port 8000 \
+ --ssl-certfile cert.pem \
+ --ssl-keyfile key.pem \
+ --no-ssl-verify
+```
+
+And open `https://:8000` to experience it. If your browser shows a warning, it’s expected for self-signed certificates. For production, use a real certificate.
+
+### DashScope API Usage
+
+To further explore Qwen3-TTS, we encourage you to try our DashScope API for a faster and more efficient experience. For detailed API information and documentation, please refer to the following:
+
+| API Description | API Documentation (Mainland China) | API Documentation (International) |
+|------------------|-----------------------------------|------------------------------------|
+| Real-time API for Qwen3-TTS of custom voice model. | [https://help.aliyun.com/zh/model-studio/qwen-tts-realtime](https://help.aliyun.com/zh/model-studio/qwen-tts-realtime) | [https://www.alibabacloud.com/help/en/model-studio/qwen-tts-realtime](https://www.alibabacloud.com/help/en/model-studio/qwen-tts-realtime) |
+| Real-time API for Qwen3-TTS of voice clone model. | [https://help.aliyun.com/zh/model-studio/qwen-tts-voice-cloning](https://help.aliyun.com/zh/model-studio/qwen-tts-voice-cloning) | [https://www.alibabacloud.com/help/en/model-studio/qwen-tts-voice-cloning](https://www.alibabacloud.com/help/en/model-studio/qwen-tts-voice-cloning) |
+| Real-time API for Qwen3-TTS of voice design model. | [https://help.aliyun.com/zh/model-studio/qwen-tts-voice-design](https://help.aliyun.com/zh/model-studio/qwen-tts-voice-design) | [https://www.alibabacloud.com/help/en/model-studio/qwen-tts-voice-design](https://www.alibabacloud.com/help/en/model-studio/qwen-tts-voice-design) |
+
+
+## vLLM Usage
+
+vLLM officially provides day-0 support for Qwen3-TTS! Welcome to use vLLM-Omni for Qwen3-TTS deployment and inference. For installation and more details, please check [vLLM-Omni official documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/getting_started/quickstart/#installation). Now only offline inference is supported. Online serving will be supported later, and vLLM-Omni will continue to offer support and optimization for Qwen3-TTS in areas such as inference speed and streaming capabilities.
+
+### Offline Inference
+You can use vLLM-Omni to inference Qwen3-TTS locally, we provide examples in [vLLM-Omni repo](https://github.com/vllm-project/vllm-omni/tree/main/examples/offline_inference/qwen3_tts) which can generate audio output:
+```bash
+# git clone https://github.com/vllm-project/vllm-omni.git
+
+# cd vllm-omni/examples/offline_inference/qwen3_tts
+
+# Run a single sample with CustomVoice task
+python end2end.py --query-type CustomVoice
+
+# Batch sample (multiple prompts in one run) with CustomVoice task:
+python end2end.py --query-type CustomVoice --use-batch-sample
+
+# Run a single sample with VoiceDesign task
+python end2end.py --query-type VoiceDesign
+
+# Batch sample (multiple prompts in one run) with VoiceDesign task:
+python end2end.py --query-type VoiceDesign --use-batch-sample
+
+# Run a single sample with Base task in icl mode-tag
+python end2end.py --query-type Base --mode-tag icl
+```
+
+## Fine Tuning
+
+Please refer to [Qwen3-TTS-Finetuning](finetuning/) for detailed instructions on fine-tuning Qwen3-TTS.
+
+## Evaluation
+
+During evaluation, we ran inference for all models with `dtype=torch.bfloat16` and set `max_new_tokens=2048`. All other sampling parameters used the defaults from the checkpoint’s `generate_config.json`. For the Seed-Test and InstructTTS-Eval test sets, we set `language="auto"`, while for all other test sets we explicitly passed the corresponding `language`. The detailed results are shown below.
+
+
+
+Speech Generation Benchmarks
+
+*Zero-shot speech generation on the Seed-TTS test set. Performance is measured by Word Error Rate (WER, ↓), where lower is better.*
+
+
+
+
+ | Datasets |
+ Model |
+ Performance |
+
+
+ | Content Consistency |
+
+
+
+
+ SEED
test-zh | test-en |
+ Seed-TTS (Anastassiou et al., 2024) |
+ 1.12 |
+ 2.25 |
+
+
+ | MaskGCT (Wang et al., 2024) |
+ 2.27 |
+ 2.62 |
+
+
+ | E2 TTS (Eskimez et al., 2024) |
+ 1.97 |
+ 2.19 |
+
+
+ | F5-TTS (Chen et al., 2024) |
+ 1.56 |
+ 1.83 |
+
+
+ | Spark TTS (Wang et al., 2025) |
+ 1.20 |
+ 1.98 |
+
+
+ | Llasa-8B (Ye et al., 2025b) |
+ 1.59 |
+ 2.97 |
+
+
+ | KALL-E (Xia et al., 2024) |
+ 0.96 |
+ 1.94 |
+
+
+ | FireRedTTS 2 (Xie et al., 2025) |
+ 1.14 |
+ 1.95 |
+
+
+ | CosyVoice 3 (Du et al., 2025) |
+ 0.71 |
+ 1.45 |
+
+
+ | MiniMax-Speech (Zhang et al., 2025a) |
+ 0.83 |
+ 1.65 |
+
+
+ | Qwen3-TTS-25Hz-0.6B-Base |
+ 1.18 |
+ 1.64 |
+
+
+ | Qwen3-TTS-25Hz-1.7B-Base |
+ 1.10 |
+ 1.49 |
+
+
+ | Qwen3-TTS-12Hz-0.6B-Base |
+ 0.92 |
+ 1.32 |
+
+
+ | Qwen3-TTS-12Hz-1.7B-Base |
+ 0.77 |
+ 1.24 |
+
+
+
+
+
+
+*Multilingual speech generation on the TTS multilingual test set. Performance is measured by Word Error Rate (WER, ↓) for content consistency and Cosine Similarity (SIM, ↑) for speaker similarity.*
+
+
+
+
+ | Language |
+ Qwen3-TTS-25Hz |
+ Qwen3-TTS-12Hz |
+ MiniMax |
+ ElevenLabs |
+
+
+ | 0.6B-Base |
+ 1.7B-Base |
+ 0.6B-Base |
+ 1.7B-Base |
+
+
+
+
+ | Content Consistency |
+
+
+ | Chinese |
+ 1.108 |
+ 0.777 |
+ 1.145 |
+ 0.928 |
+ 2.252 |
+ 16.026 |
+
+
+ | English |
+ 1.048 |
+ 1.014 |
+ 0.836 |
+ 0.934 |
+ 2.164 |
+ 2.339 |
+
+
+ | German |
+ 1.501 |
+ 0.960 |
+ 1.089 |
+ 1.235 |
+ 1.906 |
+ 0.572 |
+
+
+ | Italian |
+ 1.169 |
+ 1.105 |
+ 1.534 |
+ 0.948 |
+ 1.543 |
+ 1.743 |
+
+
+ | Portuguese |
+ 2.046 |
+ 1.778 |
+ 2.254 |
+ 1.526 |
+ 1.877 |
+ 1.331 |
+
+
+ | Spanish |
+ 2.031 |
+ 1.491 |
+ 1.491 |
+ 1.126 |
+ 1.029 |
+ 1.084 |
+
+
+ | Japanese |
+ 4.189 |
+ 5.121 |
+ 6.404 |
+ 3.823 |
+ 3.519 |
+ 10.646 |
+
+
+ | Korean |
+ 2.852 |
+ 2.631 |
+ 1.741 |
+ 1.755 |
+ 1.747 |
+ 1.865 |
+
+
+ | French |
+ 2.852 |
+ 2.631 |
+ 2.931 |
+ 2.858 |
+ 4.099 |
+ 5.216 |
+
+
+ | Russian |
+ 5.957 |
+ 4.535 |
+ 4.458 |
+ 3.212 |
+ 4.281 |
+ 3.878 |
+
+
+ | Speaker Similarity |
+
+
+ | Chinese |
+ 0.797 |
+ 0.796 |
+ 0.811 |
+ 0.799 |
+ 0.780 |
+ 0.677 |
+
+
+ | English |
+ 0.811 |
+ 0.815 |
+ 0.829 |
+ 0.775 |
+ 0.756 |
+ 0.613 |
+
+
+ | German |
+ 0.749 |
+ 0.737 |
+ 0.769 |
+ 0.775 |
+ 0.733 |
+ 0.614 |
+
+
+ | Italian |
+ 0.722 |
+ 0.718 |
+ 0.792 |
+ 0.817 |
+ 0.699 |
+ 0.579 |
+
+
+ | Portuguese |
+ 0.790 |
+ 0.783 |
+ 0.794 |
+ 0.817 |
+ 0.805 |
+ 0.711 |
+
+
+ | Spanish |
+ 0.732 |
+ 0.731 |
+ 0.812 |
+ 0.814 |
+ 0.762 |
+ 0.615 |
+
+
+ | Japanese |
+ 0.810 |
+ 0.807 |
+ 0.798 |
+ 0.788 |
+ 0.776 |
+ 0.738 |
+
+
+ | Korean |
+ 0.824 |
+ 0.814 |
+ 0.812 |
+ 0.799 |
+ 0.779 |
+ 0.700 |
+
+
+ | French |
+ 0.698 |
+ 0.703 |
+ 0.700 |
+ 0.714 |
+ 0.628 |
+ 0.535 |
+
+
+ | Russian |
+ 0.734 |
+ 0.744 |
+ 0.781 |
+ 0.792 |
+ 0.761 |
+ 0.676 |
+
+
+
+
+
+
+*Cross-lingual speech generation on the Cross-Lingual benchmark. Performance is measured by Mixed Error Rate (WER for English, CER for others, ↓).*
+
+
+
+
+ | Task |
+ Qwen3-TTS-25Hz-1.7B-Base |
+ Qwen3-TTS-12Hz-1.7B-Base |
+ CosyVoice3 |
+ CosyVoice2 |
+
+
+
+
+ | en-to-zh |
+ 5.66 |
+ 4.77 |
+ 5.09 |
+ 13.5 |
+
+
+ | ja-to-zh |
+ 3.92 |
+ 3.43 |
+ 3.05 |
+ 48.1 |
+
+
+ | ko-to-zh |
+ 1.14 |
+ 1.08 |
+ 1.06 |
+ 7.70 |
+
+
+ | zh-to-en |
+ 2.91 |
+ 2.77 |
+ 2.98 |
+ 6.47 |
+
+
+ | ja-to-en |
+ 3.95 |
+ 3.04 |
+ 4.20 |
+ 17.1 |
+
+
+ | ko-to-en |
+ 3.48 |
+ 3.09 |
+ 4.19 |
+ 11.2 |
+
+
+ | zh-to-ja |
+ 9.29 |
+ 8.40 |
+ 7.08 |
+ 13.1 |
+
+
+ | en-to-ja |
+ 7.74 |
+ 7.21 |
+ 6.80 |
+ 14.9 |
+
+
+ | ko-to-ja |
+ 4.17 |
+ 3.67 |
+ 3.93 |
+ 5.86 |
+
+
+ | zh-to-ko |
+ 8.12 |
+ 4.82 |
+ 14.4 |
+ 24.8 |
+
+
+ | en-to-ko |
+ 6.83 |
+ 5.14 |
+ 5.87 |
+ 21.9 |
+
+
+ | ja-to-ko |
+ 6.86 |
+ 5.59 |
+ 7.92 |
+ 21.5 |
+
+
+
+
+
+
+*Controllable speech generation on InstructTTSEval. Performance is measured by Attribute Perception and Synthesis accuracy (APS), Description-Speech Consistency (DSD), and Response Precision (RP).*
+
+
+
+
+ | Type |
+ Model |
+ InstructTTSEval-ZH |
+ InstructTTSEval-EN |
+
+
+ | APS (↑) |
+ DSD (↑) |
+ RP (↑) |
+ APS (↑) |
+ DSD (↑) |
+ RP (↑) |
+
+
+
+
+ Target
Speaker |
+ Gemini-flash |
+ 88.2 |
+ 90.9 |
+ 77.3 |
+ 92.3 |
+ 93.8 |
+ 80.1 |
+
+
+ | Gemini-pro |
+ 89.0 |
+ 90.1 |
+ 75.5 |
+ 87.6 |
+ 86.0 |
+ 67.2 |
+
+
+ | Qwen3TTS-25Hz-1.7B-CustomVoice |
+ 83.1 |
+ 75.0 |
+ 63.0 |
+ 79.0 |
+ 82.8 |
+ 69.3 |
+
+
+ | Qwen3TTS-12Hz-1.7B-CustomVoice |
+ 83.0 |
+ 77.8 |
+ 61.2 |
+ 77.3 |
+ 77.1 |
+ 63.7 |
+
+
+ | GPT-4o-mini-tts |
+ 54.9 |
+ 52.3 |
+ 46.0 |
+ 76.4 |
+ 74.3 |
+ 54.8 |
+
+
+ Voice
Design |
+ Qwen3TTS-12Hz-1.7B-VD |
+ 85.2 |
+ 81.1 |
+ 65.1 |
+ 82.9 |
+ 82.4 |
+ 68.4 |
+
+
+ | Mimo-Audio-7B-Instruct (Zhang et al., 2025b) |
+ 75.7 |
+ 74.3 |
+ 61.5 |
+ 80.6 |
+ 77.6 |
+ 59.5 |
+
+
+ | VoiceSculptor (Hu et al., 2026) |
+ 75.7 |
+ 64.7 |
+ 61.5 |
+ - |
+ - |
+ - |
+
+
+ | Hume |
+ - |
+ - |
+ - |
+ 83.0 |
+ 75.3 |
+ 54.3 |
+
+
+ | VoxInstruct (Zhou et al., 2024) |
+ 47.5 |
+ 52.3 |
+ 42.6 |
+ 54.9 |
+ 57.0 |
+ 39.3 |
+
+
+ | Parler-tts-mini (Lyth & King, 2024) |
+ - |
+ - |
+ - |
+ 63.4 |
+ 48.7 |
+ 28.6 |
+
+
+ | Parler-tts-large (Lyth & King, 2024) |
+ - |
+ - |
+ - |
+ 60.0 |
+ 45.9 |
+ 31.2 |
+
+
+ | PromptTTS (Guo et al., 2023) |
+ - |
+ - |
+ - |
+ 64.3 |
+ 47.2 |
+ 31.4 |
+
+
+ | PromptStyle (Liu et al., 2023) |
+ - |
+ - |
+ - |
+ 57.4 |
+ 46.4 |
+ 30.9 |
+
+
+
+
+
+
+*Target-Speaker Multilingual Speech Generation on the TTS multilingual test set. Performance is measured by Word Error Rate (WER, ↓).*
+
+
+
+
+ | Language |
+ Qwen3-TTS-25Hz |
+ Qwen3-TTS-12Hz |
+ GPT-4o-Audio
Preview |
+
+
+ | 0.6B-CustomVoice |
+ 1.7B-CustomVoice |
+ 0.6B-CustomVoice |
+ 1.7B-CustomVoice |
+
+
+
+
+ | Chinese |
+ 0.874 |
+ 0.708 |
+ 0.944 |
+ 0.903 |
+ 3.519 |
+
+
+ | English |
+ 1.332 |
+ 0.936 |
+ 1.188 |
+ 0.899 |
+ 2.197 |
+
+
+ | German |
+ 0.990 |
+ 0.634 |
+ 2.722 |
+ 1.057 |
+ 1.161 |
+
+
+ | Italian |
+ 1.861 |
+ 1.271 |
+ 2.545 |
+ 1.362 |
+ 1.194 |
+
+
+ | Portuguese |
+ 1.728 |
+ 1.854 |
+ 3.219 |
+ 2.681 |
+ 1.504 |
+
+
+ | Spanish |
+ 1.309 |
+ 1.284 |
+ 1.154 |
+ 1.330 |
+ 4.000 |
+
+
+ | Japanese |
+ 3.875 |
+ 4.518 |
+ 6.877 |
+ 4.924 |
+ 5.001 |
+
+
+ | Korean |
+ 2.202 |
+ 2.274 |
+ 3.053 |
+ 1.741 |
+ 2.763 |
+
+
+ | French |
+ 3.865 |
+ 3.080 |
+ 3.841 |
+ 3.781 |
+ 3.605 |
+
+
+ | Russian |
+ 6.529 |
+ 4.444 |
+ 5.809 |
+ 4.734 |
+ 5.250 |
+
+
+
+
+
+
+*Long speech generation results. Performance is measured by Word Error Rate (WER, ↓).*
+
+
+
+
+ | Datasets |
+ Model |
+ Performance |
+
+
+ | Content Consistency |
+
+
+
+
+ | long-zh | long-en |
+ Higgs-Audio-v2 (chunk) (Boson AI, 2025) |
+ 5.505 |
+ 6.917 |
+
+
+ | VibeVoice (Peng et al., 2025) |
+ 22.619 |
+ 1.780 |
+
+
+ | VoxCPM (Zhou et al., 2025) |
+ 4.835 |
+ 7.474 |
+
+
+ | Qwen3-TTS-25Hz-1.7B-CustomVoice |
+ 1.517 |
+ 1.225 |
+
+
+ | Qwen3-TTS-12Hz-1.7B-CustomVoice |
+ 2.356 |
+ 2.812 |
+
+
+
+
+
+
+
+Speech Tokenizer Benchmarks
+
+*Comparison between different supervised semantic speech tokenizers on ASR Task.*
+
+
+
+
+ | Model |
+ Codebook Size |
+ FPS |
+ C.V. EN |
+ C.V. CN |
+ Fluers EN |
+ Fluers CN |
+
+
+
+
+ | S3 Tokenizer(VQ) (Du et al., 2024a) |
+ 4096 |
+ 50 |
+ 12.06 |
+ 15.38 |
+ - |
+ - |
+
+
+ | S3 Tokenizer(VQ) (Du et al., 2024a) |
+ 4096 |
+ 25 |
+ 11.56 |
+ 18.26 |
+ 7.65 |
+ 5.03 |
+
+
+ | S3 Tokenizer(FSQ) (Du et al., 2024a) |
+ 6561 |
+ 25 |
+ 10.67 |
+ 7.29 |
+ 6.58 |
+ 4.43 |
+
+
+ | Qwen-TTS-Tokenizer-25Hz (Stage 1) |
+ 32768 |
+ 25 |
+ 7.51 |
+ 10.73 |
+ 3.07 |
+ 4.23 |
+
+
+ | Qwen-TTS-Tokenizer-25Hz (Stage 2) |
+ 32768 |
+ 25 |
+ 10.40 |
+ 14.99 |
+ 4.14 |
+ 4.67 |
+
+
+
+
+
+
+*Comparison between different semantic-related speech tokenizers.*
+
+
+
+
+ | Model |
+ NQ |
+ Codebook Size |
+ FPS |
+ PESQ_WB |
+ PESQ_NB |
+ STOI |
+ UTMOS |
+ SIM |
+
+
+
+
+ | SpeechTokenizer (Zhang et al., 2023a) |
+ 8 |
+ 1024 |
+ 50 |
+ 2.60 |
+ 3.05 |
+ 0.92 |
+ 3.90 |
+ 0.85 |
+
+
+ | X-codec (Ye et al., 2025a) |
+ 2 |
+ 1024 |
+ 50 |
+ 2.68 |
+ 3.27 |
+ 0.86 |
+ 4.11 |
+ 0.84 |
+
+
+ | X-codec 2 (Ye et al., 2025b) |
+ 1 |
+ 65536 |
+ 50 |
+ 2.43 |
+ 3.04 |
+ 0.92 |
+ 4.13 |
+ 0.82 |
+
+
+ | XY-Tokenizer (Gong et al., 2025) |
+ 8 |
+ 1024 |
+ 12.5 |
+ 2.41 |
+ 3.00 |
+ 0.91 |
+ 3.98 |
+ 0.83 |
+
+
+ | Mimi (Défossez et al., 2024) |
+ 16 |
+ 2048 |
+ 12.5 |
+ 2.88 |
+ 3.42 |
+ 0.94 |
+ 3.87 |
+ 0.87 |
+
+
+ | FireredTTS 2 Tokenizer (Xie et al., 2025) |
+ 16 |
+ 2048 |
+ 12.5 |
+ 2.73 |
+ 3.28 |
+ 0.94 |
+ 3.88 |
+ 0.87 |
+
+
+ | Qwen-TTS-Tokenizer-12Hz |
+ 16 |
+ 2048 |
+ 12.5 |
+ 3.21 |
+ 3.68 |
+ 0.96 |
+ 4.16 |
+ 0.95 |
+
+
+
+
+
+
+
+## Citation
+
+If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil: :)
+
+```BibTeX
+@article{Qwen3-TTS,
+ title={Qwen3-TTS Technical Report},
+ author={Hangrui Hu and Xinfa Zhu and Ting He and Dake Guo and Bin Zhang and Xiong Wang and Zhifang Guo and Ziyue Jiang and Hongkun Hao and Zishan Guo and Xinyu Zhang and Pei Zhang and Baosong Yang and Jin Xu and Jingren Zhou and Junyang Lin},
+ journal={arXiv preprint arXiv:2601.15621},
+ year={2026}
+}
+```
+
+
+## Star History
+
+[](https://star-history.com/#QwenLM/Qwen3-TTS&Date)
+
+
+
\ No newline at end of file
diff --git a/assets/Qwen3_TTS.pdf b/assets/Qwen3_TTS.pdf
new file mode 100644
index 0000000000000000000000000000000000000000..69e84f79aa2365dac881876b38c295ca141b2d13
GIT binary patch
literal 8044886
zcmZs>V|XT8(C-}^ckJX2Cbn(cwr$(ColI;ynP_6$nq*>4?Bv~h&vV}Md^r7~S9f)-
z->P2!>b|bkUEdT%#p#&nIpDqxwhp$z!7%|DfeyyjaJ;XShe6TE)z!?|oi-O9vFSwdLve^FTfZwD0y2?tdN22maMe{9MO;#RKz
z+wouH-xwHFy&TQ{p<0+Rh&b50n%TR$=&&;VJF+s6{ohcPfvimba{q1F{%!Rbl+9cm
z+?-9!T!8G1|5_O2%uKC}gdIF}{yk;mVxwo~UHWiY{)YeTA5VE&-_-8!M|L{!zv4BkfPK7e??^r;l|H20{ar`y@k0;lEXUu;)F#nB``ENhw
zzo9e#4Vn4Bh=I(1Da?N<%zr7&e<>_~DJ*{}EPp91e<>_~DIEXf@)ySP7sm1z#_|`&
z@)ySX*OT>sChjkc^)HO|e`fJ7h4n9m^)H3>FNO6#%KsMX-^>47C`|=pYcms91{F7B
z*MEf*cW}1*Z}+c^Kqdx7RWVI^aVuLhc_TYBN_qxc2MY%VOLMw^TY5)RbE>}{|LQI8
zW@l{X{D1mL*_%6vTABQ#(|-{$2>%~BnHf2NOkB+WOLbme21REF6BRSpf6`G@T<@R6
zv2}1(aWpb9`{$B~3loszzuV#eXJe2xv$t@y{6|M-F2;Yd(Dt9?We~SDay1h*GjT9A
z`zLu_T%FB~?BF~>-L|FdZO4-{e{pFHG=eC_@*CG+Se8JN0aF7tz~EW~1a}?WgU8>h
z;9$w>v)*n-w!9toclp0okNf=c`y31s?oRLAU%Pxi&jZVk5AWPxx^jv7&sPs2di?Sn
z3MW@jy}x?4`}FJYjtxROdaj7tM_13^*!C`8o_qNE@>drF6BZxt9$&pJo6c72Hy>`j
zRu5~>j_c14?q4|l@)!!rSMSc<1AKYy4OV?x73$wsAKX8Ed3y;H@cz8IdGGKO)z?ox
z;dm~bJ>0!q9;~Wz{C+!LT+7F(_Ve-Wp*K+QL-rK#%kS;$%im3?tQ$0>H>i(*`@G+N
zIyis(#D6CAef{KSTc+Ncc}iG3y?5)=hwjz&^%PEd8!S&T%C9r%y#{aQu{phGP7Zf`
z?eY(q#qH|r-}UbD&z(uAKbGCAG&cF+tCN%wz+13+Us~sO!^-Z`vDG)@y)?Yo#A{Ty
ztA2j}{-=|qxL04N9&Nwp?Ckaa7XsWvoyWI!2f5dn4ux~yuDm{d4I6Lot+=yyC+p#-
zn9WrxFs=LZ>D`Dj1CKuk=XK-|UAt40RRS|l;SY11Lm%&MuPaL*MuXy3>$3^!ukn><
z@1O773{KZ01p5zepPzN%3iXJ{4-OhXb`;G2I1N(oCS-A!d5ag1zMQ{xJ1u|6F#zhX
zBT&J6_z;(#2@|rUT?R8KXx(`X5_f6}PEaxApH`r>=#^e?S|Zzzg4Y@^=043uE!e{Q
zh_NpJB0IQ>Jj4nI4R6D07z
zvTq8;_XBq|)R_1uu(`DbB(x=5aYL@BjDMfK{-SY}I%3S2=SLgE0Hb-5%Z;jLr#Dz#
zy<|~RA9iHr58k1i<>t!c7e@r{tsa;HBjP#zenl-41^9h>$i~6eJ=H^3iqc$o@C9uD
z0-U&g^z^852E3PE$m%kjX0U*$zgo`=I}Uf+8SB(JVYAY{w3BUgvu
z!H&y`*(J}wdl!|oGW}6fFWGnN26OmSpzTAX!|;A7graBaf5KXMJHK;#^VY(XiIy;^
zug`IsOX%g+v?@d?cBq=VrIhQl-1{7~gvkw^;%(QWZaJN;TA~^(pjYDQ+CeR@KIE<7
z?Mi40;3FhD#gW@iI&`*5rZ7OA=pK#(`&rO&;>Jaa>=(P?ie4tdNtAtj%7gRgcmcI!
z0bo{vRAgi@8lBlcsZk>Y&%Q6YKt(g%lB)$TYwngkim}>+u}jB0IHR1K1dfH6qKe1B
zh;)POmyhwr-q0~wAdA@9YW~xQqW1ftS9%KLm(ktl>w5-{j>#V{^=kv-{1ufukJr%_
zx+RVnH>RP{um%d($p+7ksNG)rRUBG4;#f9P8P~96;*BTE3>3QMQ_4H}uv;U
z7B>!5ufZfwz(GN)=T8oFMdc0WgKhG$x-I=h^yWvYS>NIncM-sqfS+=JccZ?}$Q5tz
zH4%^Nke_jLK~xYCip}x#$aaJi>BMp8p|ZK9O*_C0lRlUnyc0(=q;p|;Sb7+%852U_
zdwyCGqyEaNrdX^U^C)f(8sZITS5DjV3M!Dp{E{t4`jo?C(xqr&&5z7eaXd3y6o;;P
z08=*#wC-8PVYZyDm{mVD{A-s9h|2pG?T1&K^C?7775({MmeoAQrJ2rdtZOMDYFkk|
z?{A6F0{N;OFbM!Y@_E;2JEFyq{*_JrmlzFIA;huE7$y
z7Im_X_#OzORP-D!@EJ7C<^a+0i^(0mvqPA5s{?gq;`Z~>$V>`YmlQj16qrq1IuNb(
zbE{aK(a~jiv3-O=pT@oE)B^!hth9~BV+|cGMfmIq%dyQ=9rGGaJ{Bg-+s;Fcx2nG
z*F6vnyJ@A1iiBOPOW=1mhjt{lui-SWK8IMvtroD!XTGeF!kHid^>sT%6s!EX`*wuU
zpJigoG{2sXza~ZfKX+%pZUnvv@;*OOP;Yko?$F=kqOt25z?)fng$!H42l6_q{v=p`
zy}udof6a!{f3fzoJPIHNkU!n9bdozb2Pp7YzJzf0Q9TjC;QcBf5(qs;Uc?cYyd_Gn
zHEU(OHv2Fck09p%G=xE5x#dAXW8pI)pYW`_rD*;bkDaV?*x}QBneJ@7Wl&cD`w9WR
zrxY%|9g4JKlnf<)NKGZv7+U-OcIxv{NRBK(}J`#`{$&vCVTC=#{LY}J0Rj5x$GGmbz
zsUu71Ddp8j49jwY5n+vH%X?!T(`xgUA};Sn`+YN2XOaJ_hV$3=36}uzL^MM0&ygL(
zpRu46mL^~$-1sEA&Esni?@5P+91>{&OU)kXy^;65Usdtee6`OjWgt*33pqF}hZy=R
zR6hchNxQY=^dAL1(wO5?qnjRHUDK0sep2a|pFgW-sj_KpCN#D|x7xD~8%1|wmscN+
z+!!garV!(@5LU+~9ZSTW|D;cV29^-k
zc95!r3iR+{@O?d+;L^K29UShB8W1YdK5U9`AIg6`7B;*mc(BRJ6RtdD3%xr}QGaY&
zb>q|Ta9$d;XKfJi7dZWao)zv1q2*c^_}rJq7XI-e1?sj#e(k(nkh+t=(gj6Y*6P`;
zAK=+^^hZZRVGTkkq8-!2s?ha}2=}vqw!aU3EB7~FsNyj3*Xy|B&iuA^$`KG{=y)Bb
z(SzDl!kc1IbB?!j7iz>LC6_XJgr1XDkk7H$jHNmS3Y#1MeAoH=
z1ZB$aKY>ycEDm^Yk))nuyD56O3IL58t6KswYQH9-1FdT_u?jQ7+c0m#-!%f-k?T?e
zt!hIKB2;S|qnQl1HLQv4WVgJb*c3(91!JOy&9RYHKO4ypowF;=CtDegnU8yOqhH^Oc;n|Vbjr~bf#PU
z=9th&xaf4)e2ZC!4B70tVF(8k@XT2S3l>N$4Rd0@&eyTgwlb)iT6TAJJ^=#|x3<)n
zS5V`Oka5s9>!|Us?NHL!2`w7>TL(Xrb!W8qNsd^H^lvJAV_$U^@u92=P9&6im{mrc
zA3*g!_{K#R8#RNgukWVkv;(|y0316cf0(=pujhOYVDMrW1ea%vaDQ?E(qDNz2q>){
zgMzUkH2*AFNA=d9s>FK#>YcKdE*g<|M|LuZ2dAkKQ#H<$F_MS7x($lX=r)D?Bi$#u
z1d9o`ZqgheTnNK*H*T-*s%NMGhs7)xxAkYQTXlvc1)|5G#5T526LA&Yunu2}%`)_d
z#4XeK5hcM>&>mTe*tbFBU@g!nWf)=7Ukh*;U}&Z)3ES75Z_u0<@>e^N2{jAL&Qb=y
zhG|z?H&UbdWl_H-B+8(qF&na&BP3Jv&c52s&76Bm%%wcch8ch6p*9`~TilU|YB}H2
zhq(q`RG(0{`DUQ~hQQ#G&p>W1l@)~HzF&Fr2vP2bIeW{Ansx(ZN~^H*&bgpNJQAt;=
z{PXtUrqI9GQ~P6$a{b;Yp!Q5AxV9IeHZ;zGn?RHI7EC2#2t}A$cuOxEwTkGBa(w5K
zNpvX}TBA$T_s0~x8cT9^p%j4X7E(Cx`;`}*4>h~yhhi}hr7(jFr<83U8x=bpM7gIP
z^3;scYnB)sB^_B3fWl#oqPfs~yI|P=_UO5<%u3#JXLP7K?=L_l8JUH)vpf4uptLJ<
zq?S%-@t8-WAfxik1wP?LWG_N&%QJ~s^fiW(>KS^!$4|8wGdhT-0ELCbcn`FFGIbcQ
z?gz8aqHZ>U>u8?DL%%xToHF}f@JQAi2UhQFk(3Fm
z0NAm}Khh#K1+^p017tshZmkw^2OnOtZmQVz58~p|@URm;Njq#s4^zQ7DcttdP4>EV
z>u*zZNBX%C2Q>Zm(01V3;P7)aps>iIs6C6hp(4=@{fAkH6>ci$+%kw+e!^1!h(M{7
z0@-9rlzK*2Np)70R`rdht793Lxw7_pq@uGJjW(iHJ00Qw#yc6LNwx&v}L695?o+Byv5OZ
z!K{1_0WOuK)kY%w+WrHqNk>u?_FO0az}WO4W!rKBxz)3#;L&`4-j|my&VBJ+xJB(T
z8r(nCTI6S84&(|R8gfH-(kp%RFXW~@Eh6rTvzZRdc7)7c=Q&((41*N`yNqp^OPTB(
z_z6p0Kpwm|PJ5!!kMvEJxN)PciD~vPWxorRt2NMgu7j376e3zqKIE2Mv%G^LL9h}Z
zB%z5Ie|VwtI{{!aGfdWnARailKA|fv;FNlrA@ka79n0wIj&ISn1snKHr77r#m2V@Y
zd*0Eree>oGUeebs{q7jCBRP1iS%^z~CTI%&pO!r>Znaak#u>?2A^=Hvm?x@FA(tV~
zzRdvmU09&mUirgKC~-bkuwbh5wr$}0X(e}rv!GO7t-Xme0GWl&%>`ZaNl4z`ur4Pw
z1aUdL`ILPxi#g|N!&1$cSnTe_W6BJ^Hm@aEzVYj#qEyy-R*oJvdF_#F-CsKz0%7uv
zpJG;-EJ1de#2Fhn2~k}g1KoM!Xg+cTX7qy<3)p}`Ng!L^f7Rw5ckKH
zCIix!ymTJZ)oe*f0hKQ?Jqo(b4}SjK5L9p*{>&IF2kH%mR_G+sQE{y<-7f$Zwk;`^#zYJ
z31@FVw0dG#5FU-8?Y{*xqYq?t-qr~g>1uSK$
zirF!FzyIMFY%uTJ`m;;y-NtM{1Vi8;aZO!jZ7=Bs!s>*)A{Ubc9NJS2R>y&dJdpNS9lMwpEtnxxE~_l
zjyR);ZtDu=T!}ZB{F3Wwkh0hAVZghgohcHf{uNU-vnH02
zz-$;G?%$0!)7+f>UTGU|$VfiYrfn%P%N>7Pg9k4a!K8$4_rhLEx%ilglMR)GX)KGDEhf_A!XU4u58AMia=N$z7Hs-YSPZLM}o?b
zY1`N+o?|1ske!;gR=O%ma$)RNat2h-Qn8@WjUU)L=A}1FaPkPp?{|;dtS24_tLCn$_1s(
ztmT2BfD^{ImcQ5a`mR<=5Dh`-gUE%Nw#XNObO}KsZN}(&X(%}PXXu5^e#xx&tYrni
zh7L{G(@0{ukm&mPdt4O{lK8Vrh6={YGl@+ov<{>p7ao91Z9PazhWe1t0zj}LJ1slN
z+gLdl*)Xfk9rURs3751oQ?pSqSD{rs6Q4iYIC9*oHz>-Wa8(p-m!8aik9z-CV_#!}K@9XN;%t$BbC<p0Y8iE2!r0GBd1K=`D(>+gEpC~_Gld8~=qr*EO?97I+
zg;`GxFhfESzX?}oj|8wvT!vwVUIc+>E1cYJoX{jcqvAG2!1B>t42#e@CJ9%M&9pG>
zy$;JmfkC#Gzc=5(ZcJ)Tj-9ft^0Z0;VL?!QR3X-!w9L8-uVieeO1i0)kQ;<}iE#Bo
zNUJ0hM-X*QBB*mUT6U$`)p~1;KOInLQHMn3bmO>xHWmM%bt{>mmb)~G>(_`_s=zXC
zHOO$b`I;-iGQzS3$O`Z5;HN6{w~$pIFci*@6+1^IKN9hPuRcMfPl7mMOGp0tEb1zn#t6u
zx!O~kMJ#$83C!o81Bz}y?x!un%35HalL)HEpFyDh$X=X@TdHDJ5^=l-JLuGANgRrv
zfkn;@iS5s1WGov?k6jXk!MA2mD0YUensA81Pt-*2n8GFLRJIp8pHV)#Rw6fn>3^;M
z(dI`@sFQa(>WWT9vXJ3J$i!(M+)*Ry5w>iQTyYTt&TKOT8<&VC(lrbk?oKCu!oFl8cKjoF@$_xzu=%!vn2$WJ^Tf
zgBojB++uMdc|)27DP*v)4K)Ta&yRHAz1}HDoGAhLDOZ5B()|ym78G;YWqSKY1i6Z+
zEHIyfyxkc^!AKCLd%YXB&oPSX%V1p9R@Len;*LNfK$v#iwD&v>lYE)0x=%lE9$&eA
zMGljtEoZe^e;IGIVCA^GdHxB;S{8zGqNCkI3+_VDuXeamf
zu$5zp@g^P*o+K>g^@U|S4>_cqFc*d&@_ZeIk1im64mK3rA}cTy^O-rkR^OdIluC^+
zOj5`dXd$SM5GgLEp@)1R|$8;y`^g%qs@hOlRO9F*dN9VAMJ3P;m#wmLj_h-j71gx5n$qEkuy|ky2bs_uMmX!od<#}
zw_uPaG>_}Io73aY%C5e7J|Mi#aJ{o_;gPYxGwda|4A2~jTkc8KPCWo&%#RzY0#a!*
zo^{pe8}u?eQe$@ikjSm?f{SW|V&F%+gDb`M-*HMKujsJ5Ex`bK!PpJY`GpP&rzCSG
zq>0uHgL)(u&w*y7CtoGLf_IeFEXF)A+eFev{lFs&8#IJM@YK;Y2#;?x
z`FFC*=oqt|X;!>vnbH!(wDbyX{qj?^I{oYKh~gyzDCZPB#^E6&c_QRP5bo3EXB#&R
zFuk!y+6{$`nuTPyYw+6}E6BW35W@;0VDWO4FN5<``{WhN;g0?g$95Z7TZF1Yp0G-W
z*402>H*i}U*We4IcmQ{C(sgoT;ex$jw};A`&<}8A1!1r6ctg5xRCKKd$j6{sN{t1%
ziAkU`^TDHO5b3dC@x`z`S{i%H!nO|`1SFHXH@@%`T+)@qhGw>^X;Mau=1!KK{kb4}
z&$+^s7tl=^Y^`z${_sX3a0Tgcc#QRQh4E?H-iki1LPLFZKv-gFR`0BPRX}*W|iAA<&2VNvZ?ZF=VxHO
z-gTS`OMUZ}8Xe^AdqbdDB+!`%D@*3GDUULCZYf|cmLz{@K+s#(XnnnQO6DW*1V(cB
zGJa@p-G9K78HP7m4e*nSlPs7eMmB0+>m`=V8ijnZ%1%A`6lj}*0^)wjI8VC^9eW9D
zpWD6M4GGH>VV5SLhfP>3!~k7n9#KbmUfeYtAvsp&JJ54vu-rZArg|*rPS)U+{?FH+
z&&&8jJZ<{YViz5rV|e2hUsI`&Z?Q~pi9k@7lj`^?eg+XVouk^dlNPX_>MJHQCOw;N
z`su8{ZMKjW%s9?7FaMl4otyt-AR&N3f!>KCg2(bI*pUcn1=~XvdIcKrP
z%GVbEUh=J78aP27FZWfh)!4>_Z~A={w1EsFpNyvYi0V010N54^KFRH`auPYn#h2!n
zO77e+2}%=)!zrqv;0_byjGTHW*`S9LYNN>j{Q{ZMZx}zMfwr&0E!qY|k`{(pj)EDx
z#|E+wgHh0fMZen6BhzYITXi|?S^{y~_l@L3`on_mM^~;2DTaP~D)v63tYvj*!I&T|
z9n!0AOHR2tx87b!LtZtd`5_m%v^}QP!Z!|7z4p{r3e}iU#|)ZR&AT0lwMb!r$q>PO
zmx0OQi#cJ|fEn>Xx$KIdq+K?ZZ~=26bkgpY3L1^A9Npk1G4=flQT5Q1q7ZAh>LsF&oDUtbs5xqSE|9~{>z6(c
zZ!5x7M)h0@1D63PUrH5$?O%L7N4#F5vsjwd)&Danu<%#}K|~oCrA(*;u23Lravda6Qk?v8B=vM#
z9@y-Ilc`NLl=mG=0!cTUmL@5y#7#OrXo1LVs?i&*)VyVwx!m%%=B@n1F$113r}fvo4Z=e&-iS%Da$i3}*FsZLSA?f!l-Q)>QlS`b
zN325P)|mvJ4(A|cciohBdclc}=OCogWv_kHh=zUr&br!07+ddgSo!ZbIsxwt#KEB3
zhZ2th5H^IImxA+~DOrv_E=&UHb9tYaiW`ZDrPx$xvVJa!F60p+Kyw}_KC+v~CP?HM
z+ZjmCfW@ydiXn(%!N&6~A{r`0ds8f?!s9~ckvV}i7ILBlMh!#i{kN8`xk;ATcA
z*&VJnYSUPQXT?J@Qc_GWEhzsiH5+U4@2m0Tim!+>tPL`e$ytINz2H2|Sec06?#M;g
z7#({i2eax-4V3yGnLuf+D`$_Y_J?|I(RM-v3I<#Gz|54+3wx1s!?N>1bw5B7{l^=8
zNgqG!u+z=j8l8&WtSa&VTyhL^&
zW`JMYy^CXP^-3SlV?%SLTv1>A2$g3SB*$g{>*M&bYP*;0&ku||?YtTD-KyL0=x=l<
zsuX$su4nA}{80Np4zEL^klG$0Dr&Cl1fkJdG{b8hZp3@iz~^dW8Y$d03sd8o9G*bh
zoKJ1ij$Tvy%#uHF*e)H)T|O#**7A2Hchb05^cx?j_xAnZHg_P6*yPs4n5+DBb#K4*
zX#_uFpYHEOAUh7_XhBLkX{!uqo&Mzz0r8&2Li2rHJ-NvQG{Y0pfGv9rqf)VF>vKt}
zs4VmSQ8>PjVC;-`$^KE$)e@{IZ;D@m4W531A*%2a+!wUxoUI{;UC?TAMA|{Ic@MSP
zFP|y@)ukROlS0rgbsDUcScrgoZPsOhxFcU&g2?t#Ei4N?n3;NaVfzMqQ{1btk1=%eJZjbKR6AG_F?hI=a~+{V?FwCa1X%
z$MB-zMK=-&T2Qtln~wbZ0i>3NArf1|swn~yiGQ%8qIY(+n^%>^Yq@f-El#mfh@o^-
zvFT+Qs7xaW1q5sjgBRONpIr|+yr=?D?T5)sPiPwscy~Ye)S1J>mP({VQts`{9VE9H
zy5M-I3E?t8sHKPMH;GwEl+ZCl2JX8fvC8VG;vQ4i_$QMf~6?A?)
z5Io49*!)vA1{@oF#q7wrI%VndRvcWdx2JG~bDVewFN}WxL_lJq}n{C2yk(#7y
zsz(DoBLQJ%4sr>0`zYaPaAHK(5fbW=QH7qZ=C1*o^<%4^QK=Cg+}E?8W!JI34JFm6C=2@dLUA;!qq
zL;qa@tjL3k7TjJ4k5x|^SB|_rSBV-Z?&cJHM2n%@ndieV`M1kdjg6lSes&~dVBhD%
zRA}~OIgq)6h<}QK1hFFu;RHg-Xlbks1oc9q<^Vovjq3>O4mCw*B5|_{c;!IF>HS4v
zWOa`7>JM;>&a6tT0Q=^-#Mv~C+@>Sa!4MPV)R%kpH$pA5FgJ5`pTyc%fcvK)!5)C?
zGRcuxwKI3SQu4(f1l?#7!&zfDb?*t3vw@&!@zPl$s4$YiFgArPV)h3qgqsUcQVpi5
zB{CIUlz4~4{Ag)Qfgul7MdV~0J923<1;nZj^aGNR0x7NC1;Qy811{)GI5rD%AuxzQ
zunIi|tQkUSW=>l=`#Mu32m@j?vdAtpT)YMdSAZp?^Efh^`-J~bsYj#6M(yxmI>jE2zRjK?}!@C
zbr!fcRvL(|1V1+WV~+FGX@%A-dMs-dQDr{wZnZbNv7aCY+CjI@^p
zq@W(wy8j_sD-*MryUNkN=#eZqHjJeZBn3in^wNIE=yBEn=fQz?O~8xXk*#~6IbAwF
zx%vbb&0u`xFXf_IkvEPw(G0s`^qt1c#DVJ4<~6K=zfjagJo1ym8pZv28OAFf55A#N
zBNQWSAS9Y7mZ}>i(WGFl86hZYS}O=CWq7lP?#>JOEG>n_WYpEKryWV3bL?c4r`^nG
zeU!K^$_el)^|F);VrMf-%?j|y<}-AGhl5`Nddn1rWUQh7)@(Q7V~uBqD0-OQ4jTBx
zAo;?Sd>#R}qYC66Uc+{waWUz4C&5eGzwIQhF)+N&29dd$8W&3^an!RZFWUr#`L4Yy
zk_pw3u_o9_7lghVD5upFWM1ik8gC>_n+Cka6h_wu-6Vo@og{5Qr*7z;dHZn1)I7$P
zPE_)`p=RVj%Opa{9DpZN_apF-eJQEvK5hsR%JwRYcq@NQ5?9S_b_1Rvp6|tpVdIaW
z=pc6Nj@I*Abe@ctx%Z}~PpWPw&Ee>v-ic3bHDK=4iGS}#Zo&j#*^E7C
zTv(FY6plRF9%$h$pySvSq*|nEor^=*KY=TXGLnL-yq+9^UH}GdHzN%l^gBbmeZUYw
z=qbM}*fHRxUgtQuPquDoI&`Mo)w1;_$hWwMBihzuXcjgtA3M>*Agt}}Pgyah;k5kV
zVrQ;BoO$heT6w%vZYQ3y6kv$qO-A2d*dx_+=|I-3i^P6PG~5*#3QXVFc;rKztrBvj
z<8LTV?dNR(t(HetVt@P53|GB|OJCaT?bs8AE8`8bUKhHvfI@rS06fkOgLEG(Pq2Df
zpVhiExwQ-Vof7Ms#Qck~A;&U_{EqHb%f?b~gK#=TyB#f9*-FG>=AhMH#djd1*7&I!
zy_Z2j5IqKitz3M?1c}!(w6~&`?J7F!I#xx8bW%m{E0l5vHi^fFM=8mffxArTJ?pE><8;2)#MW82t%G8NK
zqVB?*m|qf|HK(
zWY*5PD$Nad&bdv8Td9>Hl&lU7S;D_VBpIMqviX~z`cWVHCsCy4z=k+P`IV(XU7+_P
zoeD}-0}oxYb;37Pfn_W;B|3)L^$Y7BHc+*;2<45_85gU{&3ou_Cc_V&P{y-;SdQ4b
zNS+1oWt1p;aGH*jApGwq!GxDMF4>Zuqj_DCY&VRKx6HYtA&tPP#vlE+9%&MAKn$ir
zR|R03Wy7UsQ7qSos|V>9V06308o&}sngcrDSO>r}4$4WiI%|X#VGYCI3)(+79^vGw
zR9UB`ydw~d*NnWr*{)K8vEN&<%;5oiyr2oSl#hQHqFwtrM60rm@OwvkEo{?t#Tfy3
zmrW!kfzpIWiWBh=#>WRfqoly24(o%TNqv0SN|@$T3E|B3K=wHYJ-(d
zqkz7UdKbt7zjy^dtTTvh$NixH;Ox~L+q|8XpU;--h^%TZe@V(+yb@EoF9Eh93TI1(
zb;C01hjNEa>4iO=%SQg^XL?n06{v=p+srNFHsEmV4HtHShybP_4#u?%XA^e@LM71z
zm0gzJd`X+%1v8f-V~dHmlDrVq)Tpbvf+6xMM7X7|w%&L>b(Q=9Y}7n;K}6#*U|}e0
z0x^}#sVP`ipXV-kF4f&j$5|avsbr`TaBgcN9;vMD7T&Hxx1Cq}E%
zfWg-~bb6${2VDUoPc`3T5}3}=N%RO)Y0yV#kkTs4xdAg5NnyzmndQ*iAX8DS9>+7P3=CW)
zob2YupM}E{K5giF*sfL3&7v)`CecV=;W4^cP(S_PZ=dgQMF%=b|sX@;H&Gi
z=`|VV{kh`~I1^nF`o$#)0;|wnkW+3S+T)#{h7pouK3LRaA0Vd^Uz92Y%I#q4BWTR~
zlHx92DuiEOd|=Zr39?RjWW)z}7p=DUZYYRzU(Ee-?Uuy4g%EwlpO3X3p@(^ucddPn
zP`8it8$mJx{HbFf*v5q=SP3OyW?lOMGcMmCSC+3O6jJY?%bAiv
zs6V(5OgX_Qs4LjDKW_FF%YTbh^wrL;ZG^goi1_uE?(3t090CH}b*MW$%L@=tPP_UC
zBG2hYeeFXcp!o&(;zV95GaclRYf0Q0h
zr4B{83Whe+JoDI@aD~v4o?J(i+^&i^UL2kC!Z#GU>ol{S!50^GcKht}#d$%*`~XXT
z1K4@kqiYT1Ex-v`SRxJP4lFpbjUo|KJ|8R9VRCua^wQv0QmU6yt{#SV^!3iq*9IDg
zh5f-bF<^8|HQ$;fQj#ypsB(FPA>+mWr#}21X(m>7ju-QL9^Fx+o%KLx%C)?lDvjSp
zxX@@Z_L$cu+WIRZ`AWm_LuG-)+lXAu#f*;iOw`mJF}->@J>c9PmlJ2v64A?QOPJ?61ony2YR-v
zc^--R%GPJBww77+jf^18t3SVF5$2F^ssNlX_8aBSJ`Pi6A;Mly@^PJl-NSpjvJ7tj
zZ;*u{A#zSNo;ZTo7}uW;2MiDls<_y!SkUO{RerUVvXk&HUX#
zbbNd##Ve`gzy$-o2;Ux3Ygap*0>P7bk1
z$R5+R->YXC9qO4b
zFkEoRI+3nCx4KcTVR2G#d%O}XjG9&T7Yy5vne3kkOtbVLM4beJB&-RY+-C?SbaF);
z0gB+hqQO64MIm5ax_%t#NfAmhpdB`;Cs{=YlHB}&*F0QbKtosHs5k~m5vp7{yn0y&
zRHEcn%U`-_TS5knj&F|-@3J5L}Pmq44s-%No%1B!_k?(yhD96L(DR?MT
zxzMgSO`vP>u%ec3i%8uqSmI`A*!?WObzW2M@K>wsC5I>Z5xZOY;EU0Es(y`h@1x6w
zB9?R*q8yv<*;Me#E4XZ?0dKo=IP9*zw)&=zxRT7bjCG)I$9O||GnEZlhS*HSWDJa3
z*JSq{!x>%#T!I*b!Mq*cWi#kwGaf`xM2l0iN$&M>;uN`pi*Ei7>g1K1)`h-DAZ843
zlhCMxE1K&PY#M5;bejqg)P{LJ$6#6vu1FD&kem?{l#Ql$MErOs(F1;HNw&6t;N_T6
zyQ*a8XbXzrAeD_JuWNfg-UlY;&~Mz2q>i90)W&x0>YZ
zD2EzO`feA{{!7G=Gt&44NCP^df}MzO5uULAwi=}QV-s3bH_mU^g`XG;&^Zd8488Xb
zV!Vv?{$NO=QuEIF%))l`##Km&{UQBN!K{Gc>YK+%X*%}fj2Pja6I2KG`E%hx7Z;cn
z-!9Rf4>W)1jY`o0lP%(8R2Y2B+a7Cz4DPUSnjNQSKhDSCc);^%o>D;#!X*{>xd*N^
zw(AGSYy+breNeIF^l_>DMc+V72(B|fDiJy$#BBCxm^$sIXzMHVQOP+YZ@0AL8%M_?
z=FtL@C=)hc$5Yuw+f5&I5Z1>2#9iX+`9z_>49CO~x)IqC)PDb)siAjI;O6;S^%nZD
zI8J-LMs|wJkJVka<2hDQp#j?$SFmnBl}flu|L7da`y6onw>ZSO;+n|&GEe|9`W2X`
zM&`WYb!pj>+;{iPb`y+4h{^78&UEu%@RPb{DpXonY?h6+Fm29AB4*63hT*u=r2
zHgiW!HC&OsA3Dks>zlt*YS}#jcE~R9RgvFYxA)_w<|#$-z{$gw-^1g$x=u
z4WW88Gt?HY(u5$O_@T1%erL~Z5NP@2^?N~BvQZEnmZ`=`>Cj98#v87wJ`O|&*M0X8
zc^@nsW1UwCnbxw|E$aA~MA@pKsy&4#k~SIbJX=UU&NcW`0jHoHk5r^?Kk`EY`2{cV
zO8w6
zPB@=L>(~5?F^6MR&gKvnKVtxI>Kk_kj
z<_lPIhb|L8+K?vv-eCg#bvBnH?md{}*tJhB*f$$;c;IM0OP^$Z)_`FX{o%}D^I8dZ
zW9EZ1q?AMy>;K(ng?bZef+09scPzmt4la6q)+iqVm-&%?yZz6S>I2O-|95A(+RkCm
z+9Q}abc2*{Yy5Hos$~Ae6rn&Q6FY-K3J0roA#|0q0tz1+qe#2Uyb(wwN#+T&z?Q|Q
zNnjO6XB_)E9)d;G20q&ylPQUXm;`czhBOar7D=Iv`$e-)I(ff$vsegoW$@Pgvw?{#
zs83PX!%2zNMBy0oae`|pLQ!ni^rzE=VM+8Z8(#7{hjNCgqlN??Hl9VhOI9(`inb2>
zku7>~<&0sVRp`5~dn`F&T*F)71>^@m?)RhHJF3=^e47D^2}iPZmF=#*5p*!&KY{RN
z;zTWy7hd6NbII5A~
z)9)QlC0r|?za9(TAq;X(jp--k)-0bdf#c)w@DglsZ#M0*k9!2{9pEWCcO#;~PByzl
zKTrg`yq3;VH5IPLP*${EXh*lJdE|oWr(ez=(!JUsdEX9PPj0pxad`IAcCw*g<}`(e
zT}Ur-AmtSBhpD7gB2QitV3yK;xT>yK8L!!wJo=9Iyae}q{4uz*6`x?(nBJ~^#5ZB0
zPW{p+g4~S5M60=jWkK%GMm`;}*Un2xb_yl(%CbKm(f;mmt-{KjPyhB!ZUl$&_ZcD|
zW>5P?IPPar`WMeDV=fBM43?~cRSDQBm(gz-Q0r}5%(k+I0YHD|S{CD7q-acHFC>r6
zT+0OP()k7?_#Kj}ML0=T{ki4Hl=(^>v{y7uoYIM@
zEuHbE^}J{33wG=EOe#?-Gh_{-2P6Zfa~0qI5FSzW<^eM-`e
z<30o?)Fs4<6h8_(JHJ9f4Ue%-)3+w+M_7xUV&zZD0y`pFis&u*j>znvW6c9FQ$NNx^%0@MKHaQKT6Q~L
z3M;K_FUi`byC{L8MGcEW!bng^%PJNOlIpi{lr
zY`N%)Btn=5p>A@jq0RH$&t+Ai*C`;_`h@u~XeQfLfqxpSbD_1cUgTB;lIAV5(PZcy
zQ>)CN+VsIi9l2Ybe`x86-fOBop7I@2iqw)qh$4^ag%?icv2YRMX0C?4gN_h0y*I{`
zo2AkRz8@k@)<$athx+@BpmC5_0K2zK@trg?>9@(GYmlVvl4A~+ox_&^`zGVU&~Afh
z>ch&18+Fqpw8%9+p*)IpJS>5l-wYH+oNDyU7?zceSrd0U@T?+mVvBc@`vnM(2ARGs
zBvT*h4Evq0CX+ww`(%E1=sb_zx0kbWhkTQ9Jy4xl#2(~;V<4cE>2&ZXDsW@-LJ=4V
z2xsH>)RL@)T~)^Hl$Yv3cd^-kRS~q|pm(n;_%=0~Q`GY<%F4iP@`NL&MBcwSYQexZ
zSSCV_KU~hZa@UpwF=fMmec-)st>iF@g&cm%L33sXE-0(i9N=I7&gs*Je4s7A)F&2YvqABZG8qK^wGu70@k9?sQZM@|s_g?DRwBi)f?Cx&Wv5o;PU9DEK~EP($|+CF+m
z+Vl5?V%zpN#^9n*1o~f})pwJsHV<63aww#2(|L%u%*l);Tv+L`N=0^wQONwOJI^Ni
zOc)v{*CZqF&E=<2t|JV{zp#Z$sEr=|&s6`=DmSa^`DDj86$tZiHB1p$Z~LUmO4{D8
z|J>N!)IG?LYiD+{$>((1Hef*=&XWFp{&T`Bu$Hhp#4_6@?NDxeq(pnPvDn|e6wpiR
zQ;Rg~6%K>#jvG=j=!XlVrf7(I-pCL!jU-1v8zL9lv(^00#*s!hF<{U;%JFEq^UjtP
zhRPs-&;I|h_a0D9Zritb6cv>N91j8t0vN(s^$4Lv0<%u5O5V76oo)w>=I
zbGmTTVH7URd&^J1NSLP2vh#$7;Tih2*;$odq@xSv6Dd(Mk@PA3#6yQU-WGR!Iw8ld
z`*A^2HDT!p`^UE3k3hSkhM
zBy_JVXErRCLO!j99b*@;Iaqza{Dh5U*3ix67o0E1j$0d=OO{1%t#klg#pZN~J|MU*nExgv{t`
z-!FROoKI7G9>mzf&$?tfNn_8RaXuTxXK0JSl6rq8OTZmg@%@+ee;iwZ`#pdB;|abV
z=l0lfn1eu-|qtuwcIr{=>y;Yin~3cO=2jGdFODE#NQy
ze{{BjIXJ}No{hexmBD{-#sdG>VlB`Pb(zuwOR^r#MJxvVUJUfa$t9$4UOLXHVcR^vBr?T%5m7S-5|ghX?oO94EQH
zoTeNljoQ-B|w3Bt*Ck%#+#
zC&s^UX4ALW8DduZM-;N0En@@86uCVXh!;(a-T)-^@`B+Jn+}wyw>DolIsd6Mwn)`h&rKrpYf#
zTFcKY?)g?WT3y@l)SC2kT{sy3c10#mctgV|+FDq+;A%XH6d4UmOM{L54H?DhaLtF0
z43PG6l=<``ht^cvhRkl%&>;^!7uh?6)SM7!^RRtC{GydCD$)8k&-ZqLa&#QW@0RCY
zrYUNKHeC`_ab~6Tm6;a4Qhnm4k&F1jDf&`~D|3XYMgGZ_pov>?<|!{9{&DUB@PyN|oCBpqGpE^DE;q
zdSC8*G+8#Sq%9sTOHo*wMNj`py_Kvpy_e~A_ucZ~Uztkabi<{)7D;o&Sz
za?`#~{g*9lgHYw>e0zpEpZ|5GSyB|nO*wR;^|6W6nQ|%-&lYdvZ!uQGEU
zCcE~Bq46hX6|y(Ko53|}_uCzI$zEe)kk&J29aD>HZakt*X2yM~u7<;~lNY||*1Y)s
zq*yM~jrL>f$FpIur=D6Gdg|
zl01QiNq$(f=*YBreIHvIJxCiz#PWLGx1i#v!09B#zJe$Bwd$k_HI
zFQ33g_RA)=HgX2m5|-vxmKL~^iumykwE1<;61)5@T^qBL{9n)Q`5~=5yqsJ>wf{LW
zduCfW_dqy)+xuaIuYTXc5^M7dA;|xgf9o=5mHv0%s7#Ldy*R9hIDBIa5eFg;-w+_;
zK*Rwb0U{sp(IDz1kq<;Z;3Gif13nr=eIW9I$On7`hw8#8oLcVjF~LIMO(!Z!mm2>Q|MZv$GafobnDM}X5ZR1}22nKdz#xhS9vDQ?zypIQ8u(!R-xrNR
zY=!n&{3U#Uyr9WOvzv_(ov35xyz?L8c`X4
z)spV=mD1YEQ@eb+Y+_60)fmYxUxAP59ogm6gEsCLs+V@TI1hw%#=%`)upl57co((H
z7s?z8RQB!i`Sma+=}gyMz5tGFy|9~;bZziIqbj<~3;sV1!@Ex1QCkdJ`Q=~NU;XR<
zh4kG`!evy?{L_zZ+46H<6Ei&^yQvhGdE=jc>^oGu^{V!b%r`h3
z1PucIH3s0PEDKHdV-t=G&#B+9IsZ@Z|7u*hwjFw|`i_>@%hstkivP5Nzv>YQ4%k@3
zg>1{pbIJes{vp~#V2QvI8B3Ic>qIFaYV0fG=0$V`fBioy1ud}IzG!mDpOAeYG085E
zFEx?uIr>-e)d%GqLFa~6_LjNjJYS9(&$b(?jY-+XRF}D(SzCVhP9$fJ^Ul40@g2mU
zfCG+*%xDAo2kp4WdpG`9S0YJ_1BO;G;p*2O=Mce85M5$On8h
zi26X}1CbB-2oU*zj|Nd6h7A5CLTem~uIB}Ouu`-bN!bIu%NY3*$Gxbunc|0ukDK<$7*(~*76N*8V#rY7gS
zYPTtB@j0&6Sav_cGGewid{z}UTifU;-M{G*;uTISal~M^b4)%b8_dYw=ut3ZyegA?
zmSyJ!LO2HQtYKotbtfw2uBh(z%dm^4-5al8@wSJ6UsF6^v)jok&-2qz|RLnRuG~1iNMbXL{<=?_=&*J2Sip7q4qz|RLnRuG~1iNMbXL{<=?_=&*J2Sir<{~U_W7gePjBT)1bOL}K#>C%R<
z-C{`mfu9%k
zP=Ebj`H9rBBAA|D_wnJS_sR2=?g)W&@*m6l^-;O^KkA9r$VSGqX}OF_r@Nxauqc1%
zYDJ^i`jSK>2ICp&yx0m|DMveqK@kin{XFPqT5rTAdQEimFNF**;vXLm)8K~eEcny8!sq_5o=
zi$(QPD}^;V|5GHjnfF}wf@z9FGk0yAs9BD
znbDnj?3qMz>G3vSO`Wjr2NDQz6jx@d$vID0Z+G?zp0;
zJw1&Y5p#8~<8xaXQZDBG@#eoiYMB3Lt#eC5>{cZcy1N9vxlrFYV2i4*4PqPEN`ux`
z7P+Gm{Y%B%<}tKPZtK+A3(PY$6%^}F`L_B-BItg-<&Q@PRQ{u|ILSK=XDDNb*r5yF
z{^M)#qtI2_()*~EN}jpTGZE{9MKC}J=#ZJVQ)LwzTQv4Lp42tRp%i^ib{A@sT=zToWmaXF~rQ
zR~+k#ZdPV0MpUZ97wdYV$VGtl_@WS>@T#}}C=0fvzij3Y%v^h|cC9KCY)Yz2K>gOjHNlkFEd=2OoqgpLl8P*7V@koLBj
zw(y#pl>Pl8d*6*RwO6mRMNFJ~EE}rVtdeZrohl9uty&g#UkVH7NuPPk;*4I{dr!vZ`_c7Z_4><@rbl)LCTMHIWVYlv;SdAZnGy(s~1!Lx=Ivld(GUvDH(cW
zzs>L3XtS>W0Txm2sakzhrsRAd_S;nOX?K^7_V^jVCN&n5Crk29xZfRnX$O63={&xk
zt1L6y&*^9kql2`)kX?)DFIXL&VPCP-2)&@)DVrv`QRnH#E^4>M-nfS73K3oSsCs&@
z$JCCixhX2dk*#}cIFRMEFM86px*m3_cs%X2i$jD`G{R|o&23K|w!^H~cNax?c>9ZN
zoonp)8&|#zp~AMb@gnPx-TY<2*LTCjA0g#
zeWnP%kF*i|rOwqufLgSr*@%JyqlyrHmjMw2V~AWJ0WWIKtW`&F$@aO}V#2Imi}9ha
zB-7ZIthR_7^$PeVG$y>MVoW-v}^3hEk5Zq6DY=8UmLxwzQ1U0f?>~ZTTsMiPr@!~
za_pbeBuZw^X~H&v=cb}`+LTI3zR?_s8;-q}2qSLN!B<^*EX!YNPLqvaaj&69mzjIj
ziWxmQB;Hyxaf3_y+__r;NtM?=OIX(sxWMlIR+6TY-tbmt)T=Lm6&98QM16-~VzkxrjkxO3FwOlLN1
zBVJ)5Xd>i;2^2eclS5))F(@0s^J6)`KJJTs5gClST7M2@q1PPte#g0KZHcRtRT8PX
zY&|WJ4k@bCE;b`&(dg-Y3#WzGx-$0LoC-q9xNk+oTIfSUffRUw!X4zA#=RWyszo7D?fG5TPj{5uQ_`&LYoD|YC-;`@uaBYTy9zkDb|v#xOX01?
z6O@J@7|bVJtNtfU>(BWh)J8Y{hZ;X$rt|&At
z8NwJcjin>P3YX&&sv_w!OfRj?=gIO&EJkefckZdP>1G$)bu}FSj`yr3X{W(ztj{(g
z-;!=35u&k%kO_0=4MzyyLWm+~?13n!QGy-oqQqG5_>hpkmWycC*W7Cu^V&}UpyOEq$q!iYZSkx#k>rOtDx>xag*f3X||&9L?Q
zsXLWGV+)47qi>r0-IAE`R{GOnuA}C)N(SZ^eysh+N32Oz2Tmh6lm^;z?$2d-x-_0=
zYznKP9c-BqBq_3^t@ECBcWLU{V|)Omu`2nJwdKtZHnBwk-7;VH?sXp+QjBLyQENgk
zZod6IGo*~&;tk$o(fwj6b?4FM9!$yUc?+H!RIykSt0+e;3rD@e=$lh}Kl{9vzsRb{
ztW*nD%=G3dwYyw4>!xSQd%`0xH(bbt5At9y7=*?Wv6<)>*7x0
z8#B6Y!5MSHAMkKx
zg~TnogX5z*KYJ#!G@a7bO6kypzZa{u8~dykr54uadf6j6Tp@H?qRL5y{27uV7r(lh
zuEVv^XFznjy@s_cr#r!3IO~eOTXEF7cbw{D-CPqUs}%DifWJPr`IHWn+oHXjrw))l
zgLAz(*PgRDJo@IQw1s2LKx1~`dwKoVGkT8^-nj;iSq!wlUikIVpp=u9lVt)=-91%T
zyGIa|KMyF%5tXtE7_E(Tb4FRK<bV9?~)Cc~)9by_MpR
z4~A_e-u}VGrxh0V%A}fH)>yLQTKwk*kXNmey_plL6=Ve0$o-^JImb(_qU~Wo^t^d`
zSkv{WKj-?Kt!dc1jF|j{_Cn~?2|}(VEx8V_FjHb!6m5OMSTu8OG;3&sbs}kh|DKyu
z(bSx41n+=*O54<_&Yv#Esm9AM7iMu*et79PyNpbA_UIGl>=+XeZ)$H9-9lsa-12fQ
zf|o}bx@DgRzENI&z9`3Nt=F^W5O;7q(`0C6vR(TYn-oM`zjoq=A}w?7HTk%&R@TMh
zTyN3x${cKV26;$|3+B3=gpB&G3H_?%}nN3sp-$$F;j9J%TDM<
zG~3R54
zXWdU%@ybllaP3Zi2G874h_MbzW1A*9Sa5C5mNg+PL}rh~C2nDm1G%2?j@!~=u9h6Z
z)vgQkQ9=Z70%91&wz5joFeCdskeuQu%ae;|=-M6cTi=K~!zUa~y^lSdF8SK0!xMm%
z2D$qP|4aneB1mQ+M?7XjeP5pNR2`*GZ~(r63o3Kh-m(oQ3`d;Yxk{KtYY!+DfYyq@
zxTDq6XB?ruiO%Py>FG%y9Ls0E$|+X3Bt_AR|L^Z<}=f2OzErTQE3pKJce
zD0gbkz4!K3Il-&T-13lM&uq&tqP2tOqq7V5uA0Hq>QdnEL3Pr13DQ(XklPdkf48+p
zxD9#hM`(of+4!F+EUoEq*W^pNzK_EfR0tw3Q)+kOIA}dH!>X{te6<$Pk{TqpM%OPK
z+j0OcFC1Y}xYCSQF$Xcu(#w}75|<$!-jl&2GDADXMTrzRxRa4B
zz4r>syW^FZR=X~Di|{$*K}9u2eBIU?R3NeIKsec$EbdDDONW
zQ4a{ToVE1Ud-U=U96m4uV8g6d^YLi)2)Q$m>renyx-UlX9^h%+6>ZDtm~Zlva;)af
zU?$y9`FUsvG&}%oH_veLlc`7W>I4HO3$Rm=%WKnU_hUMwNqWfIfkw;Gx`{|@HyxD
z{sYrr9{4xZZHyH-g@;mkTm_Y85}VAumvJ}0c0G6@e7Lp-8!WoD=y0ou6QY?8VUFTs
z3%*@kVp7JslY-p-U~!Va7I�Z*gogf;>urPpQx2)JENp;MFG~^c^S2Ky>A0Q!#2@
z4+JxfweH%d*XQw)?;?m@lzqP;(eNoyAi2m4x#XIQ-X3Xp!_LWnd>*sKaQ`+zY`|0U
zxb!@^=E!3VC(bJUW^h9;{ulK;YX1zU0~;SsV`xqig7!WW6d|BO*|5W!dr`XDUVZ(b
z@WbpzLw5<6159Lc7ZtR#s^|s!QeJR`^4wNDJB7RY$ei0;fdWVD`chNg{LWi(qZn6L
zY0d-x=t)xfEc)gly2f9L`}>DqiEGetns9Y>{Wj9F!0c)kEytym2ptGGp5R8w=3hT-
zUa+2ol-La43-Kl3-92iHd!T3*vz2TW3GQ>n5x$RT78A3ZZC|bK#P-2}1!ho}
zErrds4TQ&wb=!;&mS#mV9NUoON=B^$lQtCvCW)c}VbpBJA`rjSR!;YYd7U{v6jIy%
z0LL?CgvfLY0j}Wb-qvqgP4R6{9xTVpm%?8{*b!$y@LIaw`8=5?Y8BkiQOZ{$KtZTS
zk~0h1mRU9u4c=RG=;ynbS-;^YpaU24azKQp!M87OWr0kV(FJVEUyLepc;}#4x5@gT
z1B^wRUtXE@%ow}_1!RnNMDik?LvA>kAsxGjTi<&EIRT5(u>Q7VPY#M_+&e43m#ybl
zRyDlIQtKncF?m^)YbH_4_Z2tGkH7#
zeOi2#w5R2Z0KEpw=U#s5Y0rgMi_+oHO@)CsMb7C@%ZA;<+-^s--Q;rzN?=QH|P7I$hiuq0#9JNBEa
z47F+gY@3o3pneb1Xw3k^2KrE-0pW>Crt8{bITeZtZn28uHHW{VSXXidO{~up;#^<0
zd;KCm`f6Yn65xEkpuOqecihE6x)5|F$Zdd~nvHNEWh&adhH7nZ%ch(cQr~RtEoM7j
z$9*c2yhwy##o$_}z_l8DyVgo@t#xU?{J#eoD5HQEysVnds&4q2i{QmsX6;*Pa%TLH
zO?w0PS-3suwvsS~^}{ynq=YWI3<#9i%v77RM>?V(W9nyK(|7*OCmg7<=C$6lxdAGu
zFBJ|a3J@I;MKt#5puMv;vycMaS?A@^Etct}b0a_lN|74pw-7@IM8ny!s5#KO?{|{VzIs55
zRzlqc+qvha{*)bq#m>I~XRNk8y-Ztwv9wGQfB-O%%w{z!A%x(8s`V|Y1RmFde$X%|
zi=1h~SR&_YX5D8-)k6>PrVEu~UVa)`I{|8U1ZXh_fvOAy93pDRs=~p%)br#`1PRY%
zYl#t}IFaQ=C`a+!7}Ws^@z(_5_IXKP;e{Y)3!_ggqJ0i;K=kCIt|;^O3Nz<8OiTgI
zqbtDO3Aib1bkWUhN$
zI1|`4TnnI^4&#@~Jfn9bPpk7t8Fz&Hpqax?FUkGtn_aU7RuU&PKkA;cB|o+~ZD~#?=NQEc
z^{#Pf8!Lh^!6u&mNz$Z1Q1Q@=Ij{Mb7=i58l0s1XV~}4k{l`g_kzmdNRcWSQIihid
z0_&2G^rAxD;}3pNymaplH38ZnRPMk=eGgS8uu;Yec%jPrr9t}%`}%dC;*4;G?j99D
zcss!u&@r@tzZ&>3-bIqfpyjM7#W7NNf~MZ*jo8x$5}pKCA=Uz9rp5v2@;8
zmtfHY?(0b1BwO_RPP^IOfZHxnyq2AyUCut_3tB>VK>_t~Z_^`!uw;&Hv@cc`05ezU
z7`_hlxM)Cd>NrI3^R#!gKQS-Oae%2|S8q}1OQTtAvFunE7-U;%{U7)Xd
z1Nr46Af_6EJfI->nmx(y2;v#i4Zx=WSF$kBAy3X*2$)@3D2g-Tv<<%dxGJQFLE+?u
zG!vEcp>VZAJ}?LxS2pQhZT`I3zsKV^82R9Ldgy~^I;qweQ_)i1pne91K^RO>ClnQB
zUF@qmUgu#mmop>2U^L$r27msXQ{|ax9B;kj*WJoerhl3`15jR)JU`
zu7>CaGtGSw-jvg;^lgS*-Jmkpid1lq3Jge3R9r3^Z$upty930)b^K!~2~#+a2qZ*f
z`^9v%Yxs-0i)HCp+=5;1Tb!BH&I`A`Lp$f`Kw66}v8iq}sMnO5HrVUHK1~so0H#BV
zJMS0BzxnH0aK2+f95)-h%#Ipy_+HyE7f%}1}l7YX6hrb`I&ht>wXgcPbpe2Ci-
zq_Q)hb%&<`9@1vN)Hy2goxHxc3a(j_6HK=~NKt;pU>1y1XQ_GqmPaG~$QtheY%6u$
zBldEz+klRJM;;{MbmY89(L{JFs1mS+=1t@WAlO?3(V5WD1|12pl*!cYATRawx%HV`
zdB3SYHjJyLaKh2P$IV_Rflbt|H`>zEWY(6-Wg?GFz44ML_&$H^_CzJoZy`6HwDUBUeM_Qqj6ajo*
z>=@3`=WGQHxi(N|ZcHoXWJ74o>e9=#d0~c|CUCg@jgQ+w1J4G_w=;=@1y8EhWkG&_
zPw#Ys^iDY94|n5kqoXJ@qrX!xJOOS+&;*vPUJPvOb4+91UVoH=y|?Kafw=Ze2xd<7
ze{7;2qH{Gpi&doWWJLJg4R0RHLSSXsL1`L)qIE-Rcy&n^-oyR-O}koHbQ0m@2m)!{
zzUM_<#iKt5)z3xO-peLf^}zwK4}sfQAjo2yp6s=`8sW^PFIxgHbqqx%#$ZO9f!VEl
zARbR%ZZCFdE_M2Vfk@$Mk6(zhZbCj7=QEY^O?vEYvY+gQ_d74LyC7h0Nm`;)%d#iP
zq6*2z9~D)omh2GIsJFOve{WQZ*kmk%uf6x&rtF#=x%EE
z>1#^$7C57Vfudf6%$0!I?bRLW*rc$X9dc55?8sO6R+Z_F5lrUG-v79tqNCOVMIIg}
z(hvHW0O@Ox*O3L}W_|)-5@h@v!Gcw7HF4cPp4B9|#dxU^(C%$LGyqyG*e>Q$oa2h6
z%)i)1E&hP1fGbXV2amZwY)`qipEI+|ED*NHpGg;}Ly&Y^M?nDsI+&z7tFJ2J(2-h>
z!|M+PhIIU*l0dx$q@MpMSS*BKv2M0=LJLE0Q9R2LRs-X9*QL08aGg0|GwQaAwN$nF
zCfcd0fe$|vRnaICDEHTn_0nD4ZV>3|eiagsOQ5scYp8gM
zwZ1-)3VGb6IHNSMm`yp3TkiTJ9y|Yvwj2yF;a8#Cw17v1V9lQy$67;>aO;*GVkf|q
zmt>)ws_NDz3}q}e4hr6f0#B22?_Co(0)Zqr5MT?l^#%87i2D}*sQ~KpZZz`T#GTWi
z_2Dw@psg&D^Ii-wY0}tH>(#S7uft)0Stz+gy))Caa0Lv=G@NGDTDf9ystKBIGM6Q!S(LPV9A;+REX|?;c
z$S4m|gZqBqFrg6*(|VT1zu8@_WYP08f*btm+LM%Vjge5ncfvck&=&WTyZoRak>mZ<
zHxu{$R**ct)wBI&;;n^dx(>Mg&aLQToM!um*T{1E(|tClXcyM|rNV(^w&f65bkD*-
zk(`am6c~M&!zQ~BsQ72(Oj~E5^RTk+lFeyv!Ho+uOx~nT6Ov*+E7?XoJ7)eKbYOD^
zlZ@~F9D>0sej#?uU)vox1JzHs*4HYaocLb+dfjep(vCoAbMT!gi`FOu+RLEc+5iGL
zO=$YAYi5adiSie*A81Ye&CU%o^+F=iz|xZLpypyl)f!N<)L6=;re`XU0Ii%Tb))V0
zfM>z1pjOYseEQJ}i%R;{uz*Z!{&3-{$+_Eg&*RAosK9WW#C(2YZMKoca^YQ$3F|${
zH1lRWlw{IWM{@fTfP3FvAJ0XH*BfG!f4Icl|HZg+@<
z92_@h(*eU)FnNKrB@z%ItB|*3Wo1zn%94N!2rAam41Ck(50IH82x!}qoAKAoJ!?ozB;lSh`Eau~J<~!Q~--Jh{75IQy>r8U(Ro~%W9xnXOt@RRDudW-%_(*t6wam+rs={Or&Ium*aBdDNSvI
znMro|YDc2ZbO}`Xs_gc61JCk}LC}BE^CSeX9(f_-3ubPa#_Ap0Z@a)S39Vrm6rC`>
zVo;5JWQ<7x9Z!}o?F)GL^xERSv-=gEoqD#H`iNxZUP*zodPDk@gQHi<_gy<+ee(BL
zze^YzoHDzpTI~R3jHrBVnf&~+wGlSpqfr4SFKq
zWJxnagh?aw1Zrl`NI6dSEOf}baI0`O6>4$#^#Y<4t#xe&6zgxNM-s2u4147U+P+H`
zArW^(PksE8C*@T?$(=oAP-FALhy-cLB-xeVeuCTWMj!5ni76`4kqu5hpy)3ZkwQ8M
zBYUSgYFA>Bv-x+y@hm41D}QsTk}?M-#H6HrG`=^v)s&dX^kk*iJwHbY-;{L{0{mM-H^8|Zr_xVL9f?|7d!wa$C@w#*|8~p073QjNW7cC-jl$M~;^jegDea~^Fnp5i
zAAhReo2f^wMRV>r#99vOY;}!1`Ryk&GwqRGjY?IY|xai@u_H
z{*GHrRg~rStJ2|iU1_MyY*B%*Ur1=36Uwu5lLzavY!orvzXx)%kub2QgdAKk_j^^)
zbXKk4V%nM0RmnbI8H1%iu11a9(b^K|Cup8^wN=T#9REaV&N`Kb{0-t1FDAnO?ulZi
zi}-oSF;(wEg?AfQ{0rdQmsR$(D|_QIE3))^5K29RT1DmA5mk2#;wx3TM92
z?6U^}&GIJ3&KT9+(BD(Mb~Vew|LN&XAso#N+c6bA1|Xskh|@d1x7C9D8CR$c49KtQ
zOGNJJ5f}!<|2!(?F(m4i-hP?mNzA?{-W#2f4wD4t6EsnV5&_EqTGwz<+}ny5#YbAo+2
zDrbT&Wv~8BxH4VEyOJe%=Pn_HY!Bh%RQwQ1d=KHDL)+I>Ci_+_u`q?3w0uiPq5aH)N4f{c!kYVSbt#vNvOGT{P
z&vT3i)}@gDzHY=Qkh*h$PVYn`o&hO4jT4M#N_c|tBJ`V<9a*l}zL7@-yDe4+;8IfB
zFuY^#NS?02sk$X{zM0ZzBVIgA5Xh2*<;B-_R(js&Yij78e|{qRInB*9mFBC`n
z6g5|+JgL6L3S}m@4;SkWQ{?H(`{2TlJHpeMd~}triQn3K(327gK}*_D_9{T}F@I&%iCKE?DLMaMzmB0}U%jOPAm-1Zwb=
z#SXxp7i>5teO;JfOMAo~kCcs8PYF|%GexBD_IkK>_SlNt4tk~#ImvnN#P-D3Cj@3i%sX(Z&N&}q!n%}b?9*Ot{m?c$)%A^KZGrTRsgx@850TgII%cB
zy}Uk#PCtJSJ{g^W0+Vp2O;&7s6
z7Suk2G*&Me)d+4co@zIu&jvT(TWb(tK(X8H
zf#lpL(D&caj4WnB;bf=>(AI~U@;PH7U||9uHg5!PA>i$CJAo3DaucRD`4Po&yeL8}
zQgf!9W7w!Us|m=y*JVDV5Vx$Nyu4|9$X8KlqBp#m(q^;ElIkE#REo^$^}#AfmPoL1
zn(A!RVg=)#d1~dOSSD@lU2IL{9VS^GW_M$=>keQ`JlVN|mw{WSzU%16@$Et9=%JAj
z{b}+kbSi4D1n)1I%3=um8a`Em@GX~BeTs*gkZ;*RD~i36O!WXzX-*T5wtWhYdZIj~T7I(`*|*qRWd
z*zyV?lo(u=k(LZ)0<8$!WJ#9MYK2-iQBf+BcI{=y3_ahuIaelbTU5j}{-Vgg2M;xY
zzbXjC%0;xhLk(AG9u$WS-K(&(kyL2uZv91Xs6CrI>+18JO
z@70^fY4ym8GtNivAi4Nrf`9yv$Q|{-k6iP&$R&w3>(dBsU(=RrXs6~^tT2xsS&-To
z%en*`l$c=CSb9K|1(FFY@{!@8RHt!`LBz(F=iby~*x3$OYq^z^WLaeP78cDrw!SEj
zc2HG(FJ&S7)C%2N>Ck4PJ
zlR~)3JoDm%-f8mRpyw^M)tacjwJBP7!jSgF*6g#L0<}L5PcYBw;O#LG{rBH>;55N6
zB4K(nrDTG>nf6Qzua)u@=o+AKj!{k2}fM66efu&C0FQ67<2
zee9%Phl2Wca3DJQ+a$Jfo9IjZ^}Xhf+is4;M;GBr;1aI(wk?iTQO?-QfuJA!kjcjy
zu9-X`25%+__d;eP;C2R$e$vfivDmHpk22=xu2oUkx#y&#ePq*S`<>2NTRDX0#K}og
zZh%^fV%7q_soOh1*%Om3h3cfS*0#NXwX}$p->AUWo3A|YpgOEbAV#l0lWZ=8`}_%;
zv{cEMeBSUnOUotg&oZ`P&S;HfgxoEs#yqJscg%ftTR(GnSMgZR=UY%gn69K=|I$WK
zP?+2OOZ`ktzGBN?ri>=4w6`kWwo5l$#k#G)N((l&gwnY&W28%tg
zt^%8QJrQl_K!%M?ZE|CW81_nkYnCilcPX)eQbA@@5e1Ee$bYV6MA;d*V{Q-Zdk+)>~Jf7RGWko~
zBrkn!n5@YKD3RJ*IjDOCluTt@Z+CWYRo?7zFfYh=ntKeghBeg1`I2h=*7bH9cTIui
zh-W4a%3BJQ%>FF?$dQ!I^An;fIfHBQfsH=tno8JtmRn$JV-#shOcsDmG9XHti*+ke
z0X_{E-nt2@ElyFLk9)qkNMc{Ju5$E=6jRD`Ontj_W67rJ$N*)pA5+Iw>;7nwIi?bu
z`>oSt$w6T*<1bsu7)7Z?;1hk?JT`ijZHrp
z<#D6E#w(}Gg7zP{oVhJk-a3NqmN~v%cyR$lM@dTRzU@iuB$dDoyOni6%vfiHr6aa}
zJeE{&<;C76f(}gEVi{&-rQn733ZE+yb0(bGh&7Uy@&j26tz;@j5|n>-h=y9IQ^`4J
zb3d&JCamV_oBOA;XkH^W;PBT$^&%zq-39eCY_7$t!x<9cIn*M~GD;wV1>b4I6N`*@
zPg#Eptk_mT)lAGIDMSmMP*O}ky8eOR9DOJ@d!?^6%hU+2EwJRZg%wcLa*VO)eG&(n
z8VRfp5d;}5cM`80fZ$sZYYns3)hn7wpwV)Bdi$%6`lFe&*>GFhU8G4rh2^}bqHYJ@
zMYqe6%}CVxP;%rwGq*X^69bzOe=%3n&!1|VCl^4#K~12USM1&y=+mry6cNUM*+J9E
zX7%yd^2jnH-GdTdJ6BYBB2T(#??Shqw6pa535(l*M>>tJjKEU;8c;`|R>A_QhV?BQ
zYXiojOL-LJMxQ`aVChMK_XK0I%WPh|{O17pb&dGv{*w27b1Q%ta0hO+69nh?r7}kJ
zt^7t5&O0TDI^CM6Rz1DcAKor48{R&xp3I6sjf+;(UN41UhkR^4(aVZ+^Gd9u$-P6YkxZ0X
zrFGZ$J%c^diKK2?`Bbv@J101)9T!g$s1QhK7iI`s;ZJ0
z^v>!e>*DO@`AC-(3*f@_NriaA%Dj4|)Y%63`(k4M9%PA
zgU@sK8+bhx@d(pzeeCBd+Y7p=g?p}3U;BxC%GynH3mvfFg8*#T>@mHM;1=ouKXMi-
zS()Uw_70L?1_sIjmfG&qvjgEl``oh`y5WmGHr}Y$NfK#@I&W$gnuz|AlAN*-R5wyu
zh%fJXl5B3y;km}O_ENu2<%q_Y6`+cJMoZJ?J9l^DR5iF&Yr|m*c1t0On<&G6p$!osFn*is*Ge*ktR$xz$MaxP%pCuVh*R%Tn9%~VigMX7|pODYh9=Wzxn
zCh?rPdX;I@eDw+S1eu}Rgopxllu7gPvn6@R
z`i~6`+U6P;XKXDPE&OjKX<>)EPMAp>Mp9ULHb;k_z8)+ZeX0yS-+kZYO&T~eD3n%4
zl;`hr;m!`I=`$04TlEz|TZEDywe&*Eefr)Yb5EGIa>tvsNnwGRbcFWdEZWkZ&a~c_
zP{z5Q%+mWqZ$iS*M`q)1Vii$I%#HKz={ZZEcxD{U;BK34!IA>N`1`L{LJRWTP{r%P
z6Xr;_0H)&pQ_^`#>diI_Su8Uc6)~`nx(Zy6VMhZKf*u$58ryEJAUZd3eb*l*ck2$m
ztK1*=-Bmhoca;@#xk6k-sVHS|IdM%vC!1bv;u4(%lw(XBu$7BQ4
z*80jJYA34{Uo2doRnRxKmZBrZiBfTYeh%2}j<)xfKj@!3?G6s;$-5BdYFZ~xXa1g?
zr9nvjiyMKd{f(7!>LuxU60zD2(1@5D&16mIdD2Y={6E{cs4~=HuA-h*dLpbLi0Pw+
zE@z>=*W`!IC_219d?4S&OnSAuaw;E#An^C`O`^&zt`-`fmD$&uK1G8qj
zs^T5Oq~mR=BFe7C;U?r9WrJQO&q9!OmK<3FqZ@#0&)&SbWVbmM+VHo4c`2VyOKg4z1R8-}ZsC2xsh|59kN5!i^dtN24SQpIr
zblm6_W$XFT)wxRaL$m^5s|3cO_)A$!_oAx?91xtMDeUce=nm|
z)Gub)gZ^1;PjU%U?&E?WbFcUk$WL^zd~6tb>#>B;kWfz75obpP)Jtg4%@9R0fUJJr^QrJLfW%fJxR>61WJIr+B`7sDuHy
z>rkMPDpe0vfzLpYn&(zD3LRr-Kbu^gzN*Q~SBf2}b!r<0+Ztt4pfST3>Pb2>CmnbW
z8@-_u7Qm&Yt2iQoT*tO$q|Suy?W;`Lv>uB_Ey){^^daQAWZCOQWv0Z=RN!Yfz$5YYse4|
zA0jV8@3b>RO>&|w98K;&W&hZz{P+BVAlCiEa^mqE)T<0&^{)se^HWg+Kk+%Jp)pwQ
zi&RZpQ7zmpXHg-gY7ar_RK^b4Wj`BJ96k8f?HQhL2Hht7f1^)f_l(cue6zi3iG_ba
zXN2@4)v+&NKIzo+zQRRFiA|7eb$&^w~j`FsXV@|OI!!!KUV?Q
z=Q3)^;M6>!=+m%ovUPjwQGMMs5$jhK8$-S4>-rz-YV8vt#k$f6x^
z%gMN=riMb8rKjHny&slAz}TTF)g0|Pv%IW`FeR#}UWBD-=^RUn_v)1*>zZ|8vaZ=p
z7E1K$jf_f@&JG`&`Sc5~xb62EP9z=>1=Td9b89+_T;Px3M28^Ke7HHi
zg^jd(W~v?LovTO;sNK*860avN6vPs=`l=^%6(Wn3?3J716<4g&=0@`;A9K{%uaApM
z={j88Fy0u6T|BkL@XcER4kXEFv6P$J4X>~1hPZ+bR^ELlu(wMw$vcIofeG%~Y_Uey
zxo60RII-}?wSYn@e@xu;LIewA>vl+RL+oGoZk(jW-|t^2f<}EJ=wgNmZGX`oa0`n(
zuCW^G8D1!&gmiDBF$}O=2m7{Db6{+wLz
z^FGy1w7cb`pC+Yu|2k}zxK{!U0gY}%Ea`m6`&IeRv?Ce0gG2JCSAPo;{qxh?58&Pl
zw!7nCOu<2xZB+HXH@_Gtz?U^IJ6kju&`p|1`w@;<4?75pCNcfk=KI4&m<35l_SKnh(-m2RFcs7jCC8
zhci&~ua2o%yLp<^7Kq*+B~+Y<5Zjo$Y_7TSVJgfCJ|_*-#svK{SI>J|F1j`O4>gD1
zQnAF)*X2Y&!7!X754y74pjW#L+MSJVQAxr6IcJvu}XY
zAA*k*+8rniO4F&?p1n?k1Bwxz@tl>31T6HP)OF28-x-`}Bel#k77~~ri*Gp4MFz-|
zBuAeQRaUoka3?Jqqj#B|%b_)`ad~E>4i2HHg!qQ9HL>?90b{k{RULo$g4(8Nv4+l2
zB4)k^bOMF=o@}a8&SsgFI0BGEr#gB0k*VfYM|3X&FDBuRb8SbN-(Y|@K;t%!+ts-dW
zSf9zJ-~VFkD+8iT->=7H6$L~Q1r<>N6$wE)6$42X=`LxI&H)TWB$bv@B&54bx9L_QW?=N
z<)aJ@?T6YH6l{f&s$}wXbJsNT8dgHOHFdAHN8VFM*~IC_eb%66fxR`B*)%?8P_drc
z72s*dG;FsTYrO|rG=!aJ314LVMEmX$3TJ>1=Ko{|KgvJna=zu?>n6Csrb-Bt?WMbo
znc44!v*I;-p+GJkNW4h7$~SCS-zT`Rmu`ZMnbSzAy9zVp!)F=eU9HLwYt>m*0IJhm
zN@*YQ;&vLyBGi|6WvWk4?G-T#VV7?_>U-&_*9m;})nHP0AWSAjongA4))Eiu!eGQ5
zHUr~;4LvjQ6a!m+NibXPer)4^sRnOhSzWoaixm@K*lZ3tH#WK4r8iHUY=+y3Gnx(W
z5F~Z^c-@%B%!uioNzRqJ;9vc^)6Ol`odKK1P6>W4ao}j11P=SGurVwS{A-cNiK?YT
zt<9>jswR>9oWKaTum97Pg@^wvPYs=%-xf8z$!~98vYFUzb`j&rC}2i@qB1tNmZaPi
z=j(s~E1=q{0j`y3USv2FprT%n=^bN*(CZbl&K63|u;*zHV_?TW`7#TptLL>QRNWhg+
z`s4(k*0{JwwCd#f(~N*d&5d`*to?pO!9CY#>P(aDOL-UNkK>Ll_~qNOM6np;cSBb0NwiA+nte%ZTnI`0H`E34NF
zm6q;QRdzifPo%`Xq?bNq2|gL{M)qecTMkhS6ckjCQxgW`vid)41=!XQ*U$aApuGJE
zhK3Vw2`RZ>-5?kIfBDNd1#tUY$hewdavtj?F!|}0FG(LM+B=x8sT-Z1R|(AwIu_;j
zO_nGcp&k2a1*UQko(~R=141~?R}YtX1G~60Ge29p=yoQlcMd3S%D&|`mJe@ryZn2H
z-XbGj>Hb^;zYM_4l;9KDYZ)s1-?|5GXvgkra!=V
zS65?lwTa-y?tN0sDLwqC>RVaD&Te_j>p?lFVnzwlvi=@t&qi(-JS}OAo;RO^?h$Tl
z037u6Rnq6YWFItB_U&{Z{xJ{WWqQ}woqrhpgf;%*(?*vGgN(^L^4p6`Z2}#O226F@
z3km1r4<&D$gyuid;_U+P3mSg;Vu?mES|$3)X2po0Vc6}AcJfE?n{$jBW0%Fr1WrXy
z-*ct*%5^yqH5X-Cw(xTIh=EJ`4#?|KeFLDuRj73BQioa6itpO0l313360>qPc%?1K
zlbu1%uJayZA29ZkCH)2V#)CqiO0mTv1NG+A>bx`>EE1O}lRP#i9Mhup_CPr*J@Dws
z`s^O4Xl{8a(P76set=OK8=tB<@+deSmss3O4m{IB9oETV_0sTw;JliU@K7Akd+TI`
zdGohX>>t+?;<)mkgH-!}oA8%?wQ3r|lM#(~BTflCkL}Vn1#o~cLRJ<|Ztz(2@Qs*;
z!cfxSQq$<>w@h8;toT@F&A+1&TU}zXn!gG>`w=y_Lq!9XgF^uN-5g^022CpgBVj{7
z_U24#g^2g#Rwh;6|5jrQMnoL@UFN8AQ_Vi}md;!e&{f$6D!=#}x!OM6a;@vo`{8v6
z+f8g&3cz3r;?~1}KyazNBh(bg)uz%B-%H%}P%T?0+h0jojZJmEUPL*7j$b`G^8uqpu+xp=Ywd
zIsKb62t_J^vk=VFmA7nlhF0IHK6O|WZ@yNje%
z!0L2xupe}m;~V@Vg~OvZVc;vVUKf7UO=6~mr2SDXQN$;Ir4U4?L=a)Z%XCgv^25$~EcEN$X&=%OEH6
zUcpjnTNdaW_xk11(oU?<c^Pa+j2Fl8$BXmdFVS^9T@D6k=5#$=}ue
z3GV?xR44plByd&f`0Y!sLF)wE>0)=vzr
z3c%w*yu|Xl?+A$E>0c_F3(8hOX;>!CScxSg&H%mi_$sRlsAl!HJcFhqz?RSmg~!&n
zIf}b7hHgHQ^?7RuonPCojD>|qc_P${_ZLUtkNx1H@X`z$WML;_SVU_PRlmp
zeX2Hl@B4BlqlxzERKf@VuK!nWA5{LVw}M*$T+dwv&+{LDPp)you!E)P@{UNMz*M9Q
zMgn4EtYGeJY{psWs==jvg0nQ>x+~L54clGdk>%FnZj5V#(0I{5Md4%?R!f7c+lrYPKx!j`Ghkd^sP6(KLAz-C0_B1k0vF&n+4~|zWPcB
zzW+Bw1;A+S*u)eiPx+$YDz$nc>$~4rAf1ni+`l%k41A!aX0NK*4VflihRON%397Q~
zTDelItTh!JoIM7>gB+kQ1=yoY0<0;hwc_N!mZGT_p{fm3(DIDK{31v5DT2n%1B`R}}0
z=qzZJ0HH~dSO5ov`5mcgFt}Q9tE`8wW{R=y8*vi4q`&&MSNvMPsDkvy!?Ort5?}%s
zWJjQFb6;U;ThV&R)-P00@vz*;r2?wBr=TwvtxzUOsemTI%!3=9?aL_$@`mM2DY$J7
zd>vTif}`|4vetD#?r$m*?-h4dp8rE&yPO6l$5WP5gb3nzCCt^|{y0l5H@WH8kSd36
zZJq?X;~o0V{FT@$TrD`H~|jR>PE
z5shzt|GH%0GrO%KGH2Q%r5*}WI?H&LqYELgGXpp4_WOApQe~~dZAC@8xkuE
zdY(IQwM1o}jAJ*c0U%4qPD@%Zn%4G5r&dK0QL`#F_JwAZ>Ug
zVnchA%Jladl#pRp_`12UdcTyrJKeVDYteZ%U(2IA*deC1R_wTv!QGx#F;Q&NT9nKD*1%|PrK56mA8w{(hif`23aj&U
z@TOAE%Rzcb@l+BYtP6Wei{cL1GkzR$-q%>Yhb+HvC@ieTSL`t3a=GNW2s`_Gvx#o9OJ#~h
zx{^cj)Kq1?=Cd=UK{B=dE^-xlM9O9TLz#L;G6BPJc}6|OawRVftKr=IR{CUR%#yB6B6h_fUg)XSYF(@Ccpjy^uB>P2
zu7hMqw)904p%vKyNW5pojTHA;_(2v|j*#CNUiDNSPQXp
z0fl6$*`-GV9mC{pdKI0u$H)Ea*BOq>HwocZc5!@Vx*n-Q3PVCT8|zkg$)yQdU|T&N
zzlt(5vneGUtq4qf;)h64ac#3lMl^^YG*(HQEvnx}W)_Q67!j^tQ{pli#;!R0dHe|1
zt=)+?@4`oq94Icy7wb1?9Z!g6Wxv#y@%6Tj0g<3d=$$xL1?xkfF`^dbovRqSF2_8M
zC_$`y(m>a0c|(73XkbUwtq+f1QOl_|eQEJ+_mnn^8S3Y17qVR{JFoR{ieH}XFd7v>
zOO@+X^<-(R{Vmo&TP%i^d@
z=Sn?r+w=5iLfjJEgR=PZ{uc!qv@ylyD4
zGWs@(TT2Vh)PshX-Bh=PGwF&jH;eRjq^^bHO>D+McQaVP3Yf+aqJj4*Ic6$N=heu51aVlm`@AvmrFa**Qn#2Q
zSw6>`nZ}`GP^LN6QQelwo1R2xU43a_WCt>xg+Fx4fx%1aLcb-Q46h6PK!c{6wmMon
zrysBg%C9!WtQMcAfKocO=R1S*VmpCjZ97z@`B1J&i1JHsbw?vRvSWDDe67lz+`M_+G;y1Po*SLh=+&72HEuCh@SnXmhL
ze_sBn7mO17rX6kSXG*bd>R}emB~=GkjQ`WGNKdBbD!X
zbW~~?|JOSu$0mGkDcr_kGFZ~y-opIUV@hjHl+f-Xjt>lW*#EHROoczj++_;Wjo|{L
zb?TvrJnJI}KR3ghj#o_M_Z>Y#hfBRM6r~{i!_BB3
zFPcE;;04ft#ZJGs34u`s9>w=ql|;tRdn%7{LIRprS42JKs$=?K)}CvXqSok+Wb#1w
z-d)H$nKU;>_8@zieaw!oV`yfPdU*_=1U?6-zoqWPIS$F7;$2jT?bjvjuG3m-E&ga}
z)C{Uz*^?iOdbp|{krl<%QboB%Yu5O=@Pv|FwO-n^PhI+3^-vXbS7c*?=(h>uo+;Zo
zi}s6kP(8DA?zXFm?Fw7a<$7?FW4t{xBpA))yN~30J
z8?B)n621CD?kMA&kR+8%z7}>HK-}Y=@WtJH9wFY|4D3>YF^dXQ=(KMRhsSury0KZxK3gV8#U14F8518U$q`9P@Ygs@5x1+4nI&
z=8mZA4d>PT3_C6{l3QO07j)+MVKu^Ts&hr+DGZMja-FRb=fj+E&HaEB##jp;ZRXr^
zDCKA3Ss3g+H=QeFosF!Rxu1S#3X`A%hai+MCDfGWqWjE#@%>%r1<3a?b{0+gNz#@F
z4ka56+g2u~WiKjbCK4Y|N?kIQmZxX%&7NjSh=c+3;0UvGDQ1{v2S5Pp$Hk%U3+^v=
z$Hv9YjdDj=ovp68C`x9_#@+FkOfstV7Sjs_cu<`G$&jmX_h>P@m=|d
zFDA9fCpS^t+_`1Hk8iTA0zq-H*WRFFMkhUbN11JR5T>$u*w_Z6Q6&)@BvnW4_yC$F
zC57~C^@r_gqT3%t98>R`aGG}h;vbkRPTZ1c=y6PY8~X9IdXDal&BaVJn){1&RqZ^1
zZM5X>FQIO+i}M@_z4JBR5*PY5%Q&W3l8$vouW&!gO-}HXE!%qs<<>TQjy?#M9|rFm
z67sPfmsr-v#1jA2$&^QAQ1h+I_agaNCWGq2LqNUb|Dj~3`%JOP5)$2duU!?A7WVB^GE^|D9fG$noOr1}&rTE0koy4*+Z?AsG>
zj@A3NPm6E$n$OZY+IL^y~WdUkgaU>Wqc
zxv(%ic;-dTRs2`6<{7zY;)@ka|F9T_wj1@?@Lo~vDN=eNBu~!m51=mNIAkzVs=UXJit9x+CZ1J|kf(@p-sKp7NDsjMHYRB`yS6>|+&B8o
zMKQ5|9nd@+(9g&qKlhf`^}1{fQ*lCyXEd0SRbC3V(Bk_WD-Y&W!Bt{t+zSdL%bVX&
za5Q&GN1GCiit_F-*=JY`epi@IH?ow$1b6Xe;K;+_r*aV~b&$8zrwzcO785(yDtMxw
z-$hmKqC@bxr|E#=R-}8hONGTwt5T1odPj09u*qDKJd4Td@Yvt=vj0HV!V-gjF2Sxu
zPx15T>%Qao;1r@B1tsH((d7Wh24l9O$xdf@tNnR!mQ_oE#^m58jC|;J+JbHIzUoM$
z@@>Bi2`6rQV;3X-j*wM-&BR6;u0)OLnwkK)Q`OWQnEa0(BP(_QxCPC>Gs*em0XV{h
zXSd*!#Nc=7i$+mvDv!4S3nbfZV-mit46Wy;q(q?=+AeqV*-NYzeM4DVib#})hqs4R
zg>YrD2{LUOtz}xuXe(9p6{Xk@)~!D;an?<-m47z(uaR>k%8uZ{;(excj4~)SmPA!EG0e)jq$kLI98hFNUG^#{wK3C!{#rCX11`5a1=)yr-$ge
zNRWj6=<;dVKPqHwim*cDKhNV-W%^{C;ugdcpP-)z){-*$UTQ}6bhr^B3uWk->}
zPSzXfcrHu{f7HkrAtxW!f}+
zb2~uZ5~g_G|HSk}P)*FdGYaF)xprqN3+?S`a03IqXIS-d!oRi{2B*Y}gVsC~Ur(3t
zG=_8YZCfjcRU2f|_6mYL#ZH
zZAC@*Iv-^YlTq9n-^hNHz1m7y(Q|3xiQulUQQOW*-V~MyMnOk`@s=;+L`n>Acf18`
z@0XAG=JIV4at5wmPyU!7@3WLkY!|8a9@H-ygIfte@rD62T-kd~b3W
zEV_l_w%c&~0Fk%XUfk}au&`2ZtaA4+H}n9+X0s})T+_S-&1U?en>Z|W+Ij6=#;jrsRfvjv{TOc3lLDtBG2D2UXsE;)5w_
z^|Sd^qImSI^clBf_SR}DN>&j6+Xltz{4UZL#Bke1Gux}nIj!|KHvX$2?T$i2(qp0}
zjR4ZEKAd}Cb0wD5h}L1vOYdNOSpn7RbOg~Iz-_=#T<5hEAUPGWhwYE+%JHXpTyrz}
zo4SezD)T14r9f`fE7)xrnPxsb7K6p>LOuq*(7S|1R5j(j?i@G46cmcUH?g*NnK^z(S
zZKvJ)wW!-(-!SKK`4$i-bgHljc*phs3b*H&3<}B~!X0cOt|Jw0;vCQ1q$G;96No&9
zX9bcdHz=|3Gg&6h(D?I@Y;*{vmh2hIw!F_j%)t;J1GHSEkU4uv6@xo{r196d+-dj`hJ
zwt#nCO$W0!p1ok|0&dFVXNw8U+&-G*Y8?%P*>5jS~h)1_;
ziN_VOktvcZ_Tn@`ycy6&JX=(JEi3PvwYfwpUGlHOSDT)gx|7q5cTumz)st`W3{WI}
zfw`F#d4nWeWSz>dJ-UHhb&cWO?#jfQKuY%-&1`L?NJy1hnC$2b;ogkUicXA<|A$b%
zY)L>UyPio%Sn$X{1kZW-<4;3)7`%xBtaFhIX}NL!Mqn$<9)L?H`n>E3pT`Y0r6b*L?8Ls%;)qSFOUyp7jnMaZi-Ss
ztMaeT;*OG=q`b21ElTO5zLjA4t;p<$=V|xziabY+y$a{TQhlUz^gq7iH;)sPyKXsV
z3{(YzShHEySNh9_f>D&(Z!lrU`@Cinj&O;h$6HiJU3yosLbn07$%z{eHiG{zrR>z~DT
zz-n_~=OtjqCZ(^Co^C+m%5-wVwsXQ8#jLaot5tj0v@1{&XM#I4+uZWq*lnF=@f)#m
zN=~EE!AC3gyC;V=9!LCZ9C|w??%B;L)t%O>5IGilT2H2yUIcS|-B9*~k#FQplC&BB
znrl!ME%_}x=HE@wS=9#8X5#~3I!dWt*&z@2m-&Q|*W;&70CobXR*^V!jp@nGKuh$l
z5gv8y#Hfz2uKUEWmT{*jS(VQc4l~4Ixj%ZuIWfW=n6-HWmzuC(&Pdq8f3zAasfOX<
zAgo5Q7m4sH2rzgs_Y$s;_F}tdqAtX}#l&)mq!CT|u$&|t8k?QGov>L~+T9t*UhBB$nq@H$!Ko&jRVnf$x)T=z8C4B5|ioNd7axQBH|;&NC;R4hPc}RY~zj
z>kwf?vs
zJ%hT_;+?&M>i2uKFw`Ahs3bQn>y|Kvl23X!k#J^X4hZuA+%vAkU$rtl#rqmD;=tc)
z(BJthOPIe*kiQ>VtqN!f`^4o;Ky-LA8+M;-C~k!{C2LSKnw(RwQP52^e?PH?v1h;e
zPKWdYY^;NIP~WCHWAi2QV^5Z#_a!h|mIth!lUnge>(5OydT&otn)A!aRknC*dsRX)
z1W=sxMdfqGF4$_0A`_E6zrl66CcfYr4VQs-o@uR5?VhcHRSZEMq;%2W8c1wLb^>$$
zGq4#>iGgRVjtIIDx2jO`t*ke{>Sj&Sz{Lk^$=WGK&&Lj0l_mLJx5K4)#vV}(9ezM9
z*A>TAPr5cg7F3^Idt7_D}2n-LhQr4
z#iVK=-45z(VZ$i*Sws?Hsnh2;qiJnl&#u@AyA}2$6Pi;+uo;JHR`hA{mh6@u@Xk_OdpCBYJIXwCLzS
zViuj2#9}gIORRLkRq{5m^A&qRu#9-GVBbOZ-}ca74bhQc^C&dmEqoVZ+X<^GExY1w
z&4c)(|L(HPp`;pvbzg{9q;dK5mSgbD-Z<8zU%(eDP+$QW&mx6jn5|4Q1izEGic%Qy
zW4~geDdkw4z7;>e^7!hCh@MlakC1a2Ep|`FBG;%w#DmtaK5VVky-%Q&uU+shY20_3
zsfmCX-WsSBIIT@8f_8~OoQVFL3KPZ4EyC#hF30KAHZv>R;cf~9;`Z;QP>-++__@6h
zk_pH2DD=LMKk(866gt5=zL~6Kr};C=Wwi4HLR!#NryN2ml7AA&55c|q=;yWEnpR^~
zUvsl5iwvwy<_uNJGP_e(cbkq|>=-M^2A?v(>&6BWn(58kLX#{>=ll0;fQE#z*AcRu
z)>oQJOS0_*N{e9V1WQ88du^-1?=M4(!;Xde75obyn5-Rmi+SsNf8ceKNBo9M!8t7o
zuj|)gDG-!}KA_gX^mx2+JK&Lj?PeZHhT6`mzc@%M?G&>>j8rjvIPE^RN|z5Dq{M6#
zC=2CUco~U;4hSm4#rKz6%Stutq9h-c<&$5oZxu2`?++)&{7;a3i$J|XjK%$bZgDVb
zUv_#x(fzG63kAOCB_UZbJjOb-X`-acSJzs$_AG>t}A505VcEYK5s
z1QJ^862Aj_rRQ1L`_4lW^$JE%BoC5F=CdA<>KgSx76yDE9|pGeM`alx
z^PmgTW-O(CtE|(JYyXO&>EAK@O_M7w5^Tm*ign^V@Y9Ew!Nxo2^g+(!fsO<@yS!u13_z`
zSB}$Eg8%}M|3ohPCYR~+a!~3TD$tH*+tt~Ju~BCwm^~lU!_p<~NCoZ`wxo}E%&Wj1
zCdX$a`t@I+^9B+gS9U}oF1VGC!BT4mKug7~S9s|`W`ohcv3>Q0AQ0Xz$exdMDLH5m
zKacs+M1YTjJ*9Hth8QjauF_Xf+u&-hjoh7o1!^4$YAxX(s30y|}x
zD5J_5-`+@2qzJ^a(Vwa@<}+dVzWz;ljr$N1WtTfr?6#d+mR}>_XFcvWumvO^GFz$#
zj*PobTV|xWQs*K>H`rSN9}N_0;e5msq~P{i=6ZKN=!kQP$_2k(mrUBew;)a@W&$k+
z`xNqu+Cpz}2{<{$fmcBGeN64$Rfd)%aWE9f0*7zs0L%SI4QiT;{b>d>5EnO4&mSO8;NPyE!R#0|v
zs1VLhbKSvDAVn7J64MEjqn5)t1vf}0rSXC%OF2ko>}h)Bs^zQa*Q>WQomJ&bVrVCu
zMNy=ZU^*ffvT`6qh6uzC6!ZV79>4Aq61WmQD!3&eQO4L+7Y7KFkPWDdNj#0hWP5+C
zv(3gJekcf2i0DA7V>3TP6k#JeVmAd}CoBCnxJY8|beUg04cn@?_A7U^%41b)Sdeq`
zFeILlq~<%oWz%Ax7BA~))
{kind=link}